 Séven Le Mesle
Séven Le Mesle
1 minutes de lecture
DevOps is dead, long live DevOps !
Rapide rappel, DevOps est né il y a environ une dizaine d'années, et plus précisément en 2007, de la tête d'un certain Patrick Debois. Il dressa un...

Mais les nombreux passionnés que nous sommes dans les communautés QA, Dev et Ops se sont eux aussi saisis de ce sujet, pour le rendre accessible au plus grand nombre.
Je voudrais vous partager dans cet article une vision claire, et accessible, de cette pratique.
D’où vient cette approche ? À quoi sert-elle ? Comment initier et faire vivre une démarche de Chaos Engineering ? Quelles sont les étapes-clés pour améliorer la résilience de nos solutions et de nos organisations en production ?
Les pannes en informatique existent depuis bien longtemps, qu’il s’agisse de bugs, d’erreurs humaines ou d’éléments extérieurs, les systèmes sont soumis à des aléas imprévisibles. Comme le dit Werner Vogels, CTO d’Amazon : “Everything fails all the time”, des pannes finissent toujours par se produire.
La probabilité d’une panne est fonction de la taille et de la complexité des déploiements.
Il est d’ailleurs impossible de prévoir et d’empêcher toutes les défaillances qui peuvent survenir au sein d’un système informatique. C’est la raison pour laquelle nous faisons depuis bien longtemps des tests de performances, des tests aux limites, des plans de reprise d’activité ou encore des ouvertures de production à blanc.
Au début des années 2000, Jesse Robbins, Master of Disaster chez Amazon, organisait ses premiers GameDay. L’idée, inspirée de son expérience de pompier, était de préparer les systèmes, les applications et les équipes à bien réagir en cas de problème. A l’époque, la solution était déjà d’injecter des pannes dans des systèmes critiques en ayant pris soin de prévenir tout le monde.
Il faudra attendre 2011 et l’adoption d’AWS par Netflix pour voir émerger le terme “Chaos Engineering” qui vient, si vous ne le saviez pas encore, du Chaos Monkey inventé par ces derniers.
La société était alors lancée dans une refonte de son parc applicatif pour adopter une architecture micro-services massivement distribuée. Dans le cadre de ce Move to Cloud, les équipes ont posé des règles de base pour leur architecture, les micro-services doivent être stateless et la perte d’une instance ne doit causer aucune perte d’état. Le Chaos Monkey s’assure que personne ne contourne cette règle en coupant des instances prises au hasard. L’idée à l’origine de ce nom est de faire entrer un singe fou dans le datacentre.
D’autres patterns de déploiement ont été retenus, tel que le déploiement sur multi-zones et multi-régions. Les services doivent continuer à fonctionner si une ou deux zones sont indisponibles. Si une région est indisponible, les utilisateurs doivent être servis depuis une autre région de façon transparente.
C’est ainsi que sont nés les agents de la Simian Army :
Tous ces outils sont les produits de la “Chaos Team” de Netflix, qui a partagé l’ensemble de ses techniques d’expérimentation dans le livre Chaos engineering, que je vous recommande chaudement.
Parmi les grands promoteurs de cette démarche, on retrouve bien sûr Netflix qui continue de partager ses outils et pratiques depuis 2011 à travers son blog technique, ses projets opensource et son livre.
La société Gremlin, fondée par Kolton Andrus, qui est à l’origine du service d’injection de panne chez Netflix, propose un ensemble de service Open et Closed Source pour faciliter la mise en pratique. Fondée en 2016, la société Gremlin s’est rapidement positionnée en évangéliste du Chaos Engineering à travers un blog, des outils opensource et sa conférence annuelle la “Chaos Conf”.
Citons aussi l’équipe d’excellence opérationnelle de Oui.SNCF, qui a repris les GameDay Amazon pour en faire un Days of Chaos afin de former et préparer l’ensemble des équipes internes (développements, opérations, management, …) à bien réagir aux pannes possibles en production.
Depuis 2014, plusieurs grandes entreprises ont créé des équipes dédiées au Chaos Engineering, c’est le cas notamment des GAFA. Mais on peut aussi citer des initiatives dans des entreprises plus conventionnelles comme la National Bank of Australia.
Il existe une communauté de 21 groupes Meetup répartis sur cinq continents, vous trouverez en France le Meetup Paris Chaos Engineering Community.
Pour chacun de ces promoteurs, l’objectif est d’améliorer la résilience des solutions et de réduire le nombre d’incidents impactant l’expérience utilisateur. Attention toutefois, le simple fait de mettre en place des injections de panne dans vos systèmes ne fournit aucune garantie de résultat en soi. Pour obtenir des améliorations sensibles, il est absolument nécessaire de tirer parti de ces expériences afin de proposer et mettre en place des améliorations techniques et/ou organisationnelles.
Si ce type d’expérimentation peut s’avérer utile à tous, son intérêt va grandissant avec la complexité de la stack technique et la criticité du système concerné.
En matière de sécurité des personnes, nous avons depuis longtemps adopté des pratiques d’entraînement, et de mise en situation :
En quelque sorte, le Chaos Engineering reprend tous ces principes en les appliquant aux systèmes informatiques et aux organisations qui les opèrent. Ils doivent avoir des mécanismes de protection et de résilience régulièrement éprouvés pour être efficaces dans les situations réelles.
Tel que défini par la communauté, le Chaos Engineering est :
une discipline de l’expérimentation sur un système distribué afin de renforcer la confiance dans la capacité du système à résister à des conditions turbulentes en production.
Il s’agit donc de réaliser des expérimentations qui testent le comportement des systèmes distribués face à des conditions extrêmes de production pour pouvoir les améliorer en continu.
Citons ici les principes du Chaos Engineering :
Certains parlent de discipline, personnellement, je préfère parler de pratique, car c’est de pratique dont il est question dans le Chaos Engineering.
Tout comme dans le cas du chat de Schrödinger, une panne qu’on ne peut constater n’existe pas. Une amélioration non mesurable n’existe pas.
Avant toute chose, il faut donc être capable de constater et observer le système dans son ensemble.
Par observabilité, nous entendons la capacité du système à être appréhendé par l’humain pour le comprendre, et l’améliorer de façon mesurable.
Pour atteindre ce but, vous pouvez utiliser des outils qui répondront à ces différents besoins :
Sans rentrer dans une étude très approfondie des solutions techniques, il faut donc pouvoir bénéficier de l’ensemble des données concernées et d’un outil permettant de les consulter aisément. Afin de permettre des réactions rapides et adaptées, on doit pouvoir définir des règles évaluées sur ces données pour lever des alertes ou notifications.
La plateforme d’observabilité doit être dynamique. Elle prend en compte les changements d’infrastructure qui sont monnaie courante dans le Cloud (autoscaling groups, création/suppression d’instances ou de services, …).
Vous pouvez découvrir ci-dessous différents composants qui peuvent être utilisés pour construire une plateforme d’observabilité :
Auditabilité
ELK - Splunk - GrayLog - Loggly - Datadog - CloudWatch Logs - StackDriver - Sentry - FluentD
Métrologie
ELK - Graphite - Prometheus - InfluxDB - CloudWatch - DataDog - StackDriver - Grafana - Zabbix - Sensu
Alerte
ELK - Grafana - PagerDuty - CloudWatch - StackDriver - Sensu
Traçabilité
OpenTelemetry - Jaeger - Zipkin - DataDog - Instana - Dynatrace - AppDynamics - X-Ray - StackDriver - Sensu
Votre système bénéficie d’une observabilité optimale, les dashboards de visualisation sont partagés et accessibles à tous. Dans votre guide des premiers secours pour système accidenté, vous bénéficiez des accès aux outils d’observabilité. En cas de problème, ils permettent d’analyser la situation de façon globale puis en profondeur.
Il existe différentes approches qui pourront être mises en place selon le contexte. Voici les étapes clés qu’il faut retenir :
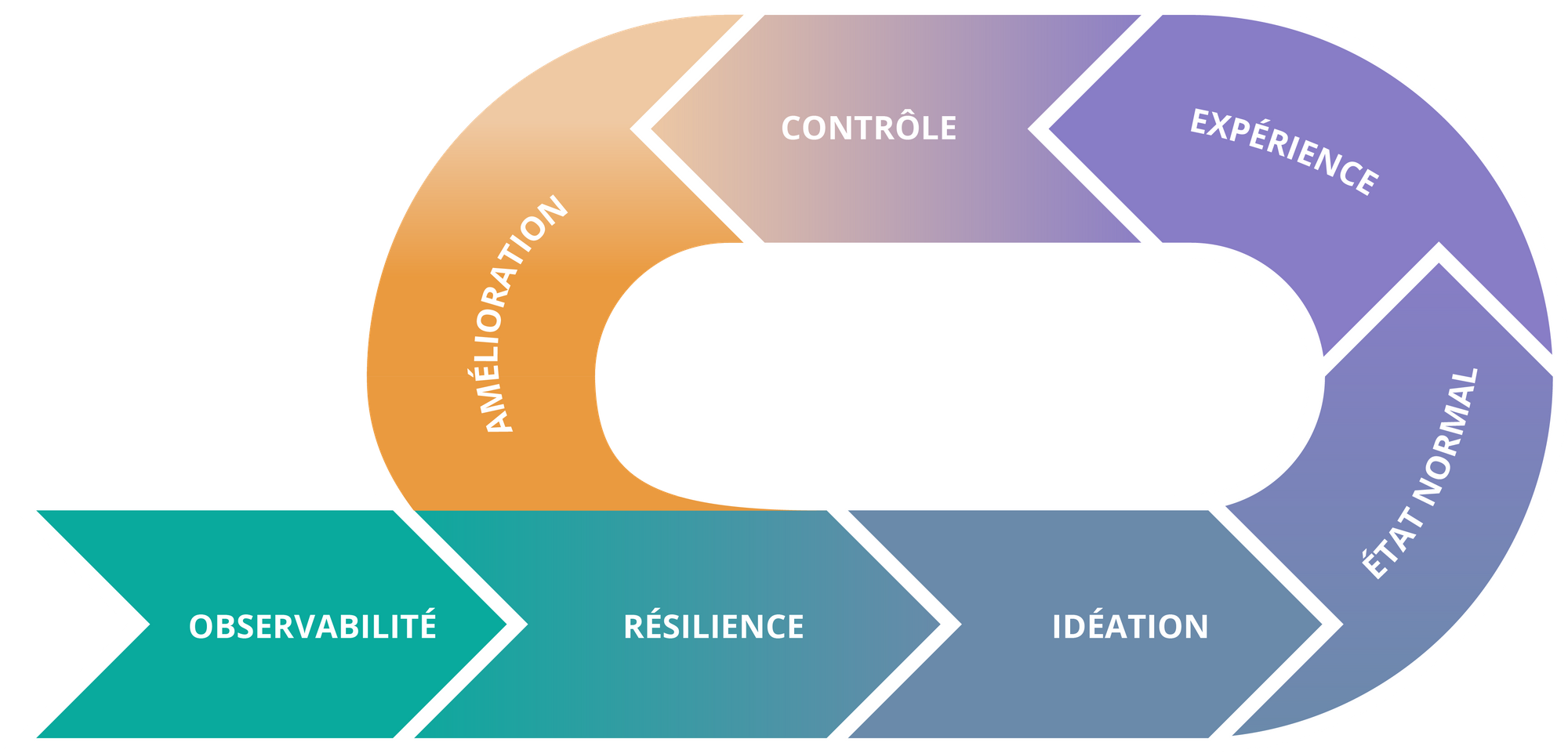
Je ne recommande pas de démarrer vos expérimentations directement en production. Il y a déjà beaucoup à faire et à apprendre sur tous les environnements hors production. La première étape est plutôt une phase d’idéation, pour répondre à des questions du type “Que se passera-t-il si …. ?”.
Commencez par réunir les personnes (techniques et fonctionnelles) en charge de l’application qui sera soumise à une expérimentation. L’atelier d’idéation sera une bonne occasion de découvrir la variété des réponses et pourra servir à aligner la compréhension de chacun.
Notre but est toujours de limiter le rayon d’impact (ou blast radius) d’une panne. Nous devons en maîtriser l’impact afin d’éviter toute perte de contrôle lors d’une expérimentation.
Les personnes réunies peuvent tout d’abord lister des pannes rencontrées dans leur passé pour créer une première liste d’expérimentations possibles. Les profils techniques ont naturellement une imagination débordante et la liste peut s’avérer un peu longue.
Quelques exemples que j’ai pu rencontrer dans le passé :
Une autre approche pour imaginer des pannes est de se concentrer sur les goulets d’étranglement connus de l’architecture et ses services critiques.
Tout peut commencer dans ce cas par le dessin de l’architecture logicielle et de l’infrastructure sous-jacente. Chaque élément peut être source de panne, on peut alors facilement en identifier et les prioriser en fonction de leur impact potentiel.
Quelques exemples :
Selon le niveau de maturité et la résilience constatée des systèmes, vous pourrez effectuer des tests dont le rayon d’action sera plus important comme la perte d’un datacentre complet.
Dans les deux approches précédentes, nous avons proposé des injections de pannes techniques afin de valider le comportement du système quand il rencontre cette panne. Il peut aussi être utile de s’intéresser à l’autonomie des intervenants, ou à la capacité de l’organisation à répondre correctement aux problèmes. Certains utilisent le principe d’injection de panne pour former les équipes.
Les scénarios peuvent donc être imaginés pour favoriser l’apprentissage d’outils et de pratiques liés à la production : fuite de mémoire de la JVM, perte de paquets réseau, mauvaise configuration d’un load balancer ou d’un reverse proxy. Lorsque vous rencontrez ce type de panne, certaines bases sont à connaître pour pouvoir analyser la situation, identifier la cause ancêtre et la corriger.
Pour les pannes retenues, vous devez être à même de vérifier le comportement normal du système.
Définissez donc l’état initial du système, quand les statuts de services indiquent une bonne santé, par exemple. Les auteurs de la panne pourront ensuite lui donner un nom et une description associée.
PANNE
Nom
Dead application instance
Description
Tue une application en cours d’exécution
Conditions initiales
L’ensemble des statuts de nos services sont en vie, le taux d’erreur web est faible, les temps de réponses sont inférieurs à 300ms
Environnement technique
Quelle application, quelle stack technique, quel environnement est étudié ?
Contexte
A quoi doit nous servir cette panne, quel est son impact fonctionnel ? Quel est son impact temporel ?
Comportement attendu
Comment le système doit-il réagir à cette panne ?
En combien de temps ?
Solutions
Quelles solutions peut-on envisager pour que le système réagisse de la façon espérée et comment corriger et identifier le bug s'il existe ?
Cette fiche descriptive est une étape importante car elle servira d’une part de spécification pour la future expérimentation, et d’autre part parce-qu'elle permet d’exprimer les réponses attendues du système. Si on reprend la fin spontanée d’une application, on peut imaginer que le système relancera l’application en question ou qu’une nouvelle instance viendra la remplacer.
Attention, le comportement réel constaté est bien souvent très différent de celui imaginé au départ. Ne vous méprenez pas, c’est une très bonne nouvelle car c’est grâce à cela que l’équipe apprendra à mieux connaître son système.
Au point où nous en sommes, il est temps de mettre en pratique, et pourtant nous avons oublié un point déterminant : “Comment identifier l’impact ? Quels sont les indicateurs à observer ?”.
Pensez-y, toute expérience de Chaos Engineering doit être lisible et persistée dans la plateforme d’observabilité. N’oubliez pas de définir le mode d’observation envisagé pour la panne.
Si vous souhaitez tester la réaction de votre organisation, vous pouvez aussi ajouter en dernière note de la spécification de panne, les rôles concernés, le mécanisme d’escalade et plus globalement les interlocuteurs à prévenir.
Pensez à vous équiper d’un référentiel de panne, qui vous permettra de capitaliser sur l’ensemble des tests réalisés. Un wiki ou un espace de documentation fera parfaitement l’affaire, mais il existe aussi bien sûr des solutions prévues à cet effet. Vous pouvez par exemple découvrir la plateforme commerciale de ChaosToolkit développée par la société ChaosIQ et dont il existe une version opensource.
L’expérimentation ne peut être lancée que sur un système initialement stable. Pour une première tentative, vous pouvez commencer manuellement. Dans le cas de la panne citée plus haut, vous pouvez terminer le processus de l’application en lui envoyant un SIG_KILL par exemple.
Mais avant cela, vous devez avoir prévu une méthode pour revenir à l’état initial, car nous n’avons pas la garantie que le comportement imaginé sera bien celui constaté. Dans le cas où les choses tourneraient mal, soyez prêts à intervenir rapidement pour revenir à l’état stable.
Dans le cadre de cette remise en marche, vous aurez besoin de certains outils et accès pour pouvoir opérer, évitez donc de réaliser des expériences qui vous priveraient de vos moyens de rétablissement (SSH, réseaux, …).
Les expérimentations doivent être clairement notifiées à l’ensemble de l’organisation. La résilience est l’affaire de tous, il ne s’agit pas d’une aventure isolée.
Il est temps de tirer des enseignements de l’expérience. Vous pouvez compléter une fiche d’expérience qui reprendra les bases de la description de panne, mais précisera cette fois la date du test, l’environnement d’exécution, le mode opératoire complet, le comportement constaté et enfin, la solution ou les solutions à mettre en place pour améliorer la résilience du système.
Concrètement, il existe deux possibilités :
Attention, avoir validé une fois la réponse du système à une panne particulière, ne vous garanti pas que le comportement sera toujours valide. N’oublions pas que les régressions existent, et que les environnements sont la plupart du temps différents du développement jusqu’à la production.
Parlons maintenant d’automatisation : attention, je ne suis pas en train de vous dire qu’il faut injecter en masse des pannes de façon automatique sur votre production et surtout pas des pannes que vous n’avez pas testées ailleurs. Il s’agit de découvrir les faiblesses inconnues en maîtrisant l’impact pour les utilisateurs.
Bénéficier d’outils permettant d’injecter automatiquement des pannes dans les environnements de production facilite grandement la réalisation de ces expériences. Certains diront à raison que la production n’est pas un environnement de test ou un laboratoire d’innovation. Pourtant, c’est bien en production que la résilience est critique et qu’elle doit être continuellement validée.
On peut se poser une question simple : “Souhaitez-vous que les utilisateurs des services en production fassent eux-mêmes l’expérience des défauts de résilience de vos systèmes ?” Cette pensée est bien sûr critiquable, mais en fin de compte le risque est là. À l’heure des réseaux sociaux et de l’étalage public, les utilisateurs constatent régulièrement les anomalies de vos services et ne manquent pas de le faire savoir au plus large public possible. Il n’est pas rare que les Tweetos soient au fait de vos problèmes avant même les équipes internes.
Faire appel à un outil et automatiser doit vous permettre de minimiser les risques pris en production. Les pannes et le retour à l’état stable sont scriptés sans intervention humaine.
Il est essentiel de définir un périmètre d’exécution qui pourra aller d’un utilisateur à une instance ou plus, en fonction du comportement constaté. Les pannes qui sont injectées par un automate doivent être clairement annoncées, via les mécanismes d’alerte standards.
Idéalement, vous avez un référentiel et un tableau de bord commun à toutes les injections de pannes qui peut jouer le rôle d’orchestrateur et vous offre des fonctionnalités avancées pour gérer finement le périmètre d’injection d’une panne :
Parmi les solutions qui ont retenu mon attention, je peux citer :
Ces deux outils vous proposent un langage descriptif pour définir vos pannes, l’état stable du système et le mécanisme de reprise en cas d’erreur. Ils intègrent chacun une notion de ciblage ou de scope pour définir où et comment injecter la panne.
Notez que ChaosToolkit définit une Open API qui propose de standardiser la description des scénarios de pannes dans un format JSON.
Je vous invite à consulter le blog technique de Netflix qui évoque leurs solutions internes FIT et ChaP pour gérer l’injection de pannes en production et surtout en continu.
Si l’on suit à la lettre les principes de l’ingénierie du Chaos, il faut limiter le rayon d’impact de vos tests. L’objectif est de découvrir des défauts sans trop impacter les utilisateurs. Si à la suite d’une injection de panne, votre système connaît un incident majeur, la partie “réduire le rayon d’impact” n’aura sans doute pas été suffisamment réfléchie.
Je distingue deux choses en réalité se cachant derrière le dernier des cinq principes. La première est bel et bien de limiter au maximum l’impact potentiel pour les utilisateurs lors de l’injection d’une panne. La deuxième doit faire partie de la boucle de feedback des expériences car il s’agit d’améliorer le comportement, et donc la conception des services ou applications pour limiter l’impact d’une panne ou d’un bug les concernants.
Voici quelques règles essentielles pour limiter le blast radius :
Dans le dernier point, nous touchons à l’architecture du système. Qu’elle soit applicative ou d’infrastructure, la résilience doit se construire sciemment. Je ne ferai pas ici la liste des méthodes et solutions qui existent pour gérer les cas de pannes, cela pourrait faire partie d’un article à part entière. Le principe de base qui doit s’imposer est de ne jamais considérer que les dépendances de l’application sont toujours disponibles et fonctionnelles. Il est essentiel de prévoir et de mettre en oeuvre des comportements qui s’adapteront en fonction du contexte.
Nous le savons aujourd’hui, les pannes existent et finissent toujours par se produire. Le fonctionnement des systèmes de production est bel et bien chaotique par essence. Il existe un grand nombre de facteurs qui peuvent causer des incidents de production :
Il ne faut pas attendre qu’un incident arrive pour améliorer la résilience des systèmes. Vos utilisateurs ne doivent pas faire les frais des indisponibilités incontrôlées. Les expériences de Chaos Engineering permettent de découvrir les défauts de résilience sans causer d’incidents de production graves. L’observabilité est essentielle pour pouvoir réaliser des tests en constatant leur impact sur le système et l’organisation. Nous cherchons à fiabiliser la production. Pour minimiser l’impact métier d’une panne, nous avons donc besoin de pouvoir observer la variation induite par ladite panne. La plateforme d’observabilité nous permettra aussi de réaliser une analyse fine des anomalies découvertes.
Attention, il n’y a pas de recette magique, éprouver la résilience des systèmes en confiance n’est pas simple. Cela pose des problèmes techniques mais aussi et surtout des difficultés pour aligner les différents organes du cycle de production complet. Je recommande de commencer par sensibiliser les équipes à travers des ateliers d’idéations de pannes, et des évènements de mises en situation comme des GameDay,. Enfin, gardez en tête que la tolérance aux pannes est un comportement construit dans les systèmes et leurs composants, vous devez donc l’intégrer dans vos normes de développements et d’opérations. Vous devrez aussi adapter vos architectures pour garantir un parfait contrôle du scope de vos tests en production.

1 minutes de lecture
Rapide rappel, DevOps est né il y a environ une dizaine d'années, et plus précisément en 2007, de la tête d'un certain Patrick Debois. Il dressa un...

Introduction Lorsqu'on souhaite entamer la consolidation d’un système d’information, il est important de s’intéresser à la centralisation des logs...
