Prometheus Starter Kit
Description Prometheus est une solution open-source (Apache 2.0) de monitoring et d’alerting développée à l’origine chez SoundCloud. Il a été le...
6 minutes de lecture


En d'autres termes, le chaos engineering (CE) permet aux ingénieurs de découvrir l'impact des incidents de production sur l'utilisateur final. Le CE peut être appliqué grâce à des outils open source ou bien propriétaires, en exécutant différents types de perturbations sur un système d'information dans le but de renforcer sa résilience.
Le CE répond à la question fréquente : "voulez-vous être sûr du "bon" fonctionnement de votre système ?"
“There's no better way to test something than to break it”
Matt Fornaciari co-founder,CTO of Gremlin Inc
Un système résilient :
Attention, on doit éviter la confusion entre la résilience et la robustesse.
Un système robuste :
Le chaos engineering n'est pas un simple test ou une méthode qui sert à nuire au système. Il s'agit d'établir et implémenter une discipline d'apprentissage à travers des expérimentations sur le système. Le but est de renforcer la confiance dans son environnement, quelle que soit sa complexité.
Avant de passer à l'implémentation du Chaos Engineering, on doit tout d'abord vérifier la nature de notre système :
Contrairement à un système centralisé, un système distribué est composé de plusieurs entités logicielles s'exécutant indépendamment et parallèlement sur un ensemble d’hôtes connectés en réseaux. Dans un système distribué, l'utilisateur et les entités n'ont pas besoin de connaître les détails de l'architecture système.
L’intérêt de l'utilisation des systèmes distribués réside dans l'utilisation et le partage des ressources distantes, l'optimisation des ressources disponibles et la robustesse grâce à la duplication qui assure une certaine fiabilité.
Parmi les principales caractéristiques des systèmes distribués :
Hétérogénéité : la diversité des systèmes d'exploitation (Centos 7, Windows 10...), différents hôtes (puissance, architecture, matérielle...), des langages de programmation des éléments logiciels formant le système, des réseaux utilisés (impact sur la performance, le débit, la disponibilité...)
Transparence : dans le but de cacher l'architecture, le fonctionnement de l'application ou du système distribué apparaît aux utilisateurs comme une application unique cohérente. Il existe plusieurs types de transparence (l'ISO définit plusieurs transparences (norme RM-ODP Reference Model-of Open Distributed Processing)).
Un système complexe est un système distribué composé de plus petites unités et en évolution en fonction du temps. Ces entités se répartissent en fonctions clés au sein du système. De nombreux styles d'architectures permettent de réaliser de tels systèmes, comme ceux basés sur les micro-services qui sont capables d’évoluer en ajoutant d’autres micro-services au système.
J’apprécie beaucoup la description faite sur le blog de Xebia :
“Un micro-service est avant tout une unité fonctionnelle. Il correspond à une fonctionnalité précise, logique et cohérente du système.
Il est donc autonome vis à vis de la fonctionnalité qu’il réalise. Il a son propre code, gère ses propres données et ne les partage pas - pas directement en tout cas - avec d’autres services.
Dans ce style architectural, un service correspond, de plus, à un processus système indépendant. Dans certains cas, un micro-service peut être constitué de plusieurs processus mais l’inverse n’est pas vrai. Une conséquence de ce constat est que les services communiquent entre eux par des appels réseaux et non par des appels de fonctions en interne dans un processus.
Un micro-service est donc une unité de service fonctionnelle qui se développe, se déploie, s’exécute et gère ses données indépendamment des autres services du système.”
On pourra avoir du chaos dans les systèmes réguliers (la latence, la charge des CPU, …).
Les systèmes complexes et distribués représentent les meilleurs candidats à l’échec.
Avant de commencer à tout “détruire”, il faut s’assurer d’avoir un état d'esprit qui correspond à la démarche du chaos engineering :
Le chaos engineering nécessite de la communication et de l’hétérogénéité au sein de l’équipe. La coordination entre les membres de l'équipe sert à faciliter la connaissance de l'état stable du système qui va être soumis aux expérimentations.
L’équipe s'organise et se concentre en formant un cercle d'échange d'expertises. Elles doivent susciter une symbiose entre des compétences complémentaires.
Avant de s’intéresser à ce prérequis, il est indispensable de définir quelques termes en relation avec le Monitoring.
On commence par la métrologie; cette méthode permet d’archiver les données relevées et d’effectuer des traitements dessus, notamment grâce à des mécanismes de filtration. Le but est de les présenter sous forme de graphes pour faire du reporting. Ces données serviront à apporter des correctifs à posteriori, sur le développement ou le paramétrage des services dans le but de les optimiser. La métrologie devient alors très importante car c’est elle qui donne la possibilité d'améliorer la qualité de service.
On passe ensuite à la supervision. Elle sert à vérifier l'état d'un service ou d'un hôte. La supervision remonte une alerte sur la détection d'un comportement anormal (la latence par exemple).
Le monitoring est le fait de superviser des équipements et des services et détecter les évolutions du système dans le temps grâce à la lecture des courbes de données métriques.
L'utilisation de l'outil de monitoring dans le cas du chaos engineering est indispensable pour connaître l'état du système à chaque attaque de chaos. La visibilité sur le comportement du système permet de tirer les conclusions des expérimentations de chaos.
Avoir un système distribué n’est pas un prérequis, malgré tout, le graphe suivant représente un arbre de prise de décision qui vous permet de vous rapprocher des conditions idéales :
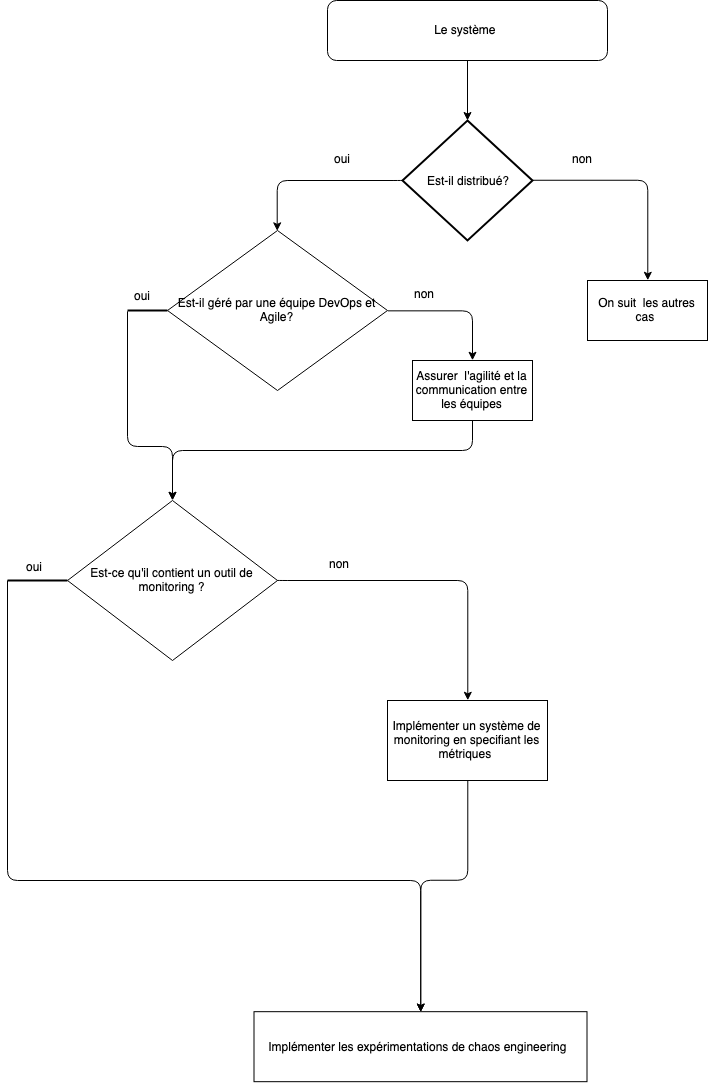
Les prérequis indispensables pour une bonne implémentation du Chaos sont les suivants :
Netflix défini des guidelines pour adhérer à une certaine philosophie de l’alerting.Pour pouvoir appliquer du chaos engineering, il faut être sûr de la mise en place d'un système d'alerting.
Les alertes doivent obéir avant tout aux principes suivants :
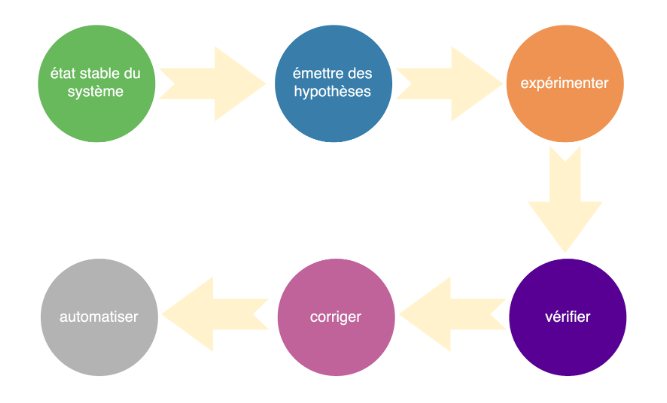
Netflix a identifié 4 principes pour désigner une expérimentation de chaos :
Ces principes mènent à définir les phases de CE :
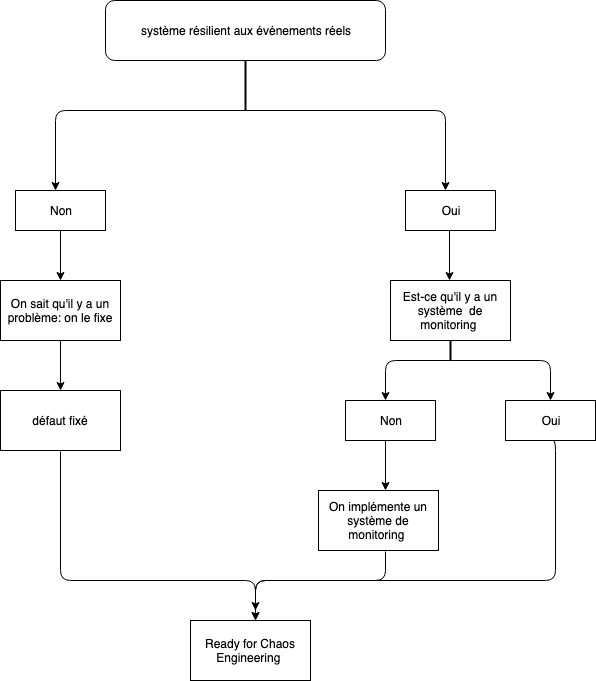
Quel est cet état ? Comment puis-je l'identifier ?
Cette question sera à la base d'une équipe compétente et maîtrisant son système. Des réponses vont y être apporté à l'aide du monitoring et de la collecte de métriques (KPI, latence, taux d'erreur ...). Vous apporterez également des réponses avec la compréhension et la définition de la satisfaction des utilisateurs du système.
Pour toute expérimentation, Il est nécessaire de faire une hypothèse qu’on vérifiera via l’expérimentation de chaos.
C'est pour cette raison qu'on développe les hypothèses autour de l'état stable du système. Si on sait que l'expérimentation entraînera des perturbations sur l’environnement de production (après dialogue avec l’équipe qui maîtrise le système), on devra la repousser. On doit tout d'abord travailler à renforcer la fiabilité du système avant d’expérimenter dessus, il ne s’agit pas de le casser.
Dans cette étape, on effectue les tests et les expérimentations en commençant par des tests simples. Ces tests peuvent affecter la disponibilité des micro-services centraux afin de tester la résilience du système. Parmi les tests courants, vous trouverez par exemple des tests de défaillance de matérielle, surcharge de ressources, injection de latence et de défaillance réseau, etc.
Par la suite, on passera aux expérimentations de chaos utilisant des outils qui s’appliquent sur le système global (cela doit être préparé par une étude).
Pour cette étape, on compare les résultats obtenus par les expérimentations aux métriques de l'état stable du système. Puis, on corrige les erreurs et les problèmes pour renforcer la résilience du système.
Pour des implémentations efficaces de Chaos Engineering, l'automatisation des tests et l'exécution des expérimentations sont nécessaires. Netflix a développé ChAP (Chaos Automation Platform) qui est une plateforme d'automatisation de chaos (Nous en parlerons bientôt dans le prochain article).
Le chaos engineering peut être injecté dans les différentes couches du système. J’aborderais ce point plus en détail dans mes prochaines articles mais vous pouvez tout à fait imaginer faire du chaos sur vos APIs, dans vos applications, bases de données, systèmes de cache, vos hôtes et leurs OS, le réseau, l’énergie ou même sur vos équipe
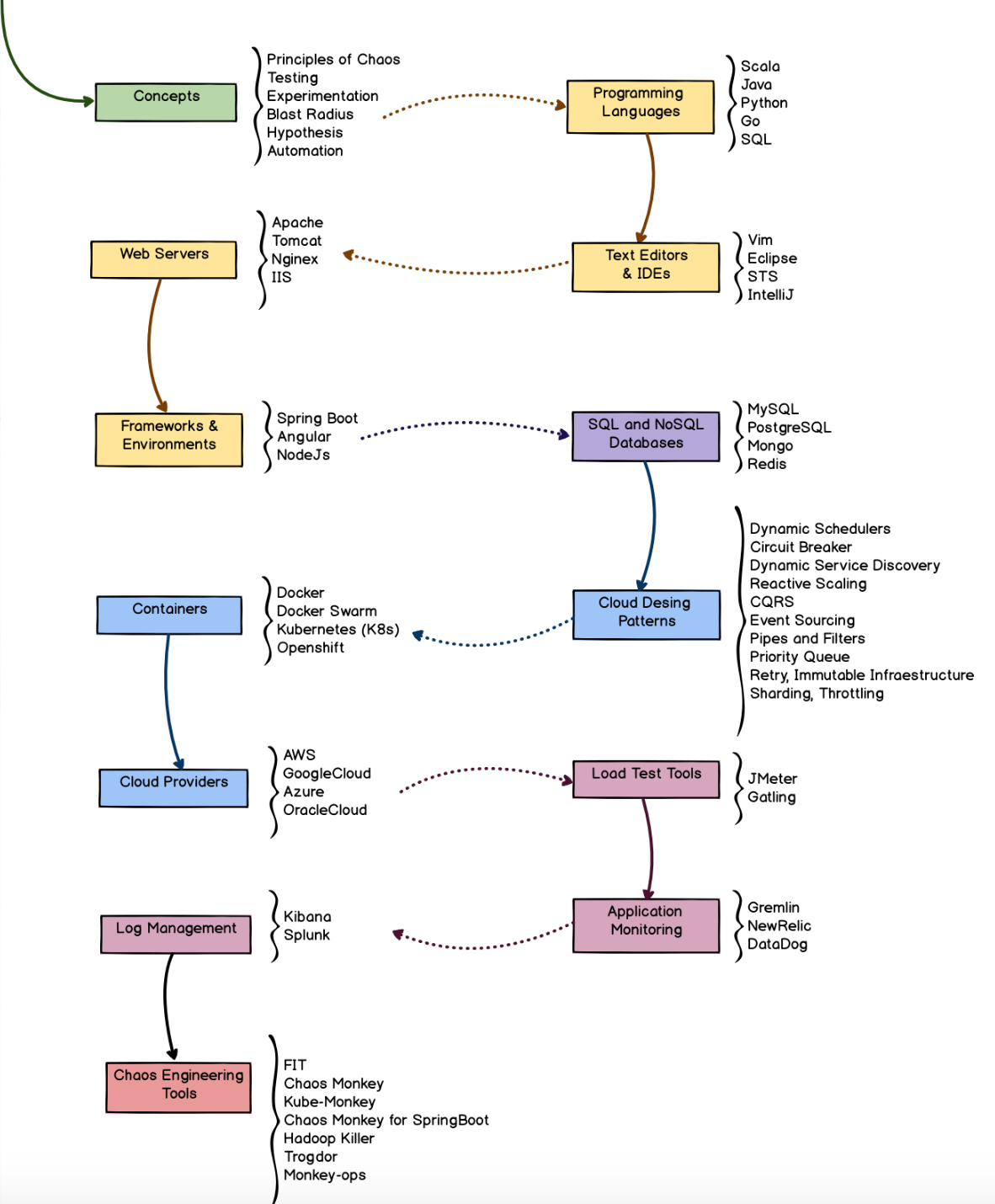
Une RoadMap a été réalisée par Yury Niño, l'une des grandes enthousiastes du Chaos Engineering.
Elle illustre les différentes technologies applicatives, de base de données, de conteneurisation, d'architectures cloud etc, que l’on rencontre sur le chemin que nous venons d’emprunter et que l’on devra surement apprendre à maîtriser pour devenir un ingénieur du Chaos.
Il faut commencer par avoir une idée des concepts de CE tels que les phases et les principes. Ensuite on doit définir les domaines (représentés par les couleurs) où l'on veut faire du chaos (par exemple le niveau applicatif, cloud…) et une partie des technologies à connaître jusqu’au choix des outils de CE à utiliser.
Cette RoadMap reste évidemment toujours ouverte à des nouveaux concepts et technologies qui favorisent l’implémentation de CE.
Parmi les bénéfices à retirer de la pratique du Chaos Engineering, ce qui me motive le plus est :
Une deuxième et une troisième parties suivront prochainement cet article. On parlera des outils Open Source de Chaos Engineering existant et je vous présenterai également un REX sur le sujet.
PS : I want to thank Russ Miles and Sylvain Hellegouarch for their help into becoming a Chaos Engineer.
Description Prometheus est une solution open-source (Apache 2.0) de monitoring et d’alerting développée à l’origine chez SoundCloud. Il a été le...

Mais les nombreux passionnés que nous sommes dans les communautés QA, Dev et Ops se sont eux aussi saisis de ce sujet, pour le rendre accessible au...
