 David Drugeon-Hamon
David Drugeon-Hamon



Tutoriel : architecture serverless avec AWS Lambda et Terraform
Objectifs Il y a des modes en informatique et l’utilisation de “BuzzWord” est fréquente. Dans les derniers de ceux-ci, un terme revient souvent :...

AWS propose depuis de nombreuses années le développement de services sans serveur dits serverless. Même si le nom est galvaudé - un serveur est toujours présent pour pouvoir exécuter votre code - nous pouvons nous concentrer uniquement sur notre code métier. Les opérations sur les serveurs hébergeant notre application ne sont plus nécessaires (Maintenance, correctifs de faille de sécurité, montée en scalabilité horizontale comme verticale, etc.). Et généralement, AWS ne facture que les services à la demande et propose un « Free Tier » assez élevé.
Malgré ces nombreux avantages, il devient difficile de déboguer, de tracer les requêtes et de recueillir les fichiers journaux applicatifs.
Comment rendre observables nos applications serverless ? Quels sont les outils proposés par AWS ? Y a-t-il des moyens simples pour ajouter de l’observabilité à nos applications ?
J’essaierai d’y répondre dans la suite de l’article.
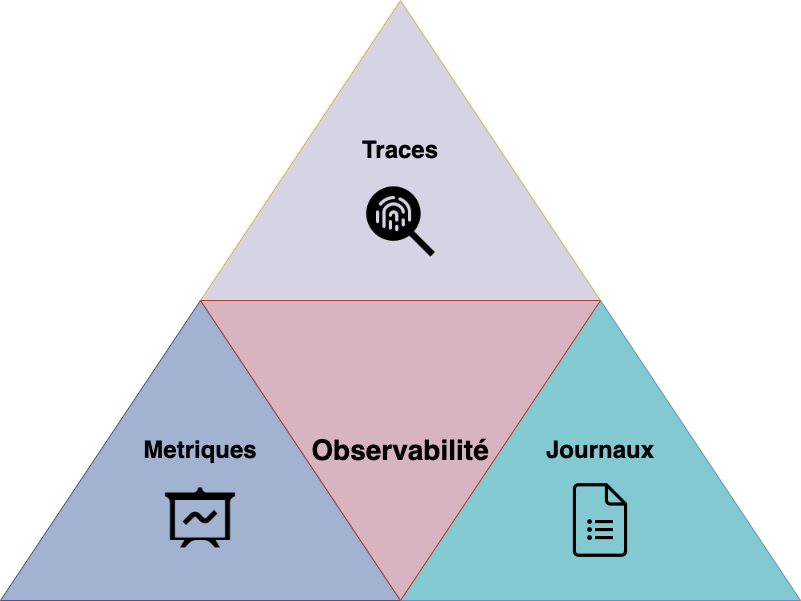
En physique, un système est dit observable si nous pouvons déduire son état à partir des données qu’il produit. Par analogie, nous pouvons observer les différents états d’une application distribuée ou d’un système informatique complexe à partir des données qu’il produira au cours du temps.
Quelles sont ces données, me direz-vous ?
Un premier type correspond aux traces (aussi appelé tracing). Dans une application distribuée, différents services interagissent pour traiter une requête utilisateur. Nous avons besoin de connaître les interactions entre ces composants, le temps pris par chaque service pour traiter la demande et comprendre les goulots d’étranglement.
Pour réaliser ce fil d’Ariane, nous générons un identifiant unique lorsque la requête est émise sur notre système. Cet identifiant unique est ensuite transmis de service en service, ce qui nous permettra de tracer le chemin pris.
Les outils Open Source sont Jaeger et OpenTelemetry. Néanmoins, de nombreuses solutions propriétaires prennent en charge les données de tracing.
Le deuxième type représente les métriques de tous les composants de notre architecture.
Les métriques correspondent à une mesure à un instant T sur un système :
Elles permettent d’avoir une vue sur l’état de santé de notre système et d’être alerté en cas d’incident.
Prometheus est le système open source d'agrégation des métriques le plus connu et le plus déployé sur un environnement Kubernetes.
Le dernier type correspond aux journaux (communément appelés logs).
Ce sont des fichiers texte horodatés qui permettent de comprendre le fil de l’exécution d’une application avec éventuellement un niveau de criticité du message. Généralement, nous installons un agent sur le système pour collecter ces messages au fil de l’eau pour les envoyer vers un outil de journalisation centralisé. Grâce à la centralisation des données, nous pouvons facilement recueillir les journaux, les agréger et les analyser ce qui facilitera l’interrogation en cas d’incident sur notre application.
De nombreux outils permettent de collecter les journaux, par exemple : fluentd, logstash. Pour l’indexation et la recherche dans les données, nous proposons généralement un environnement ElasticSearch.
Dans le monde Kubernetes, l’outil open source Loki commence à être de plus en plus populaire.
Pour chacune des données issues de ces trois piliers de l’observabilité, nous pouvons ajouter des informations complémentaires appelées métadonnées. Nous indiquons par exemple depuis quel hôte la donnée a été émise, le type d’environnement, la région AWS sur laquelle l’infrastructure a été déployée, etc. Ces métadonnées sont stockées sous forme de paires de clés / valeur, ce qui permet ensuite de filtrer les données lors d’une recherche.
L’outil d’observabilité collecte et indexe ensuite ces différentes données temporelles avec leurs métadonnées dans sa base de données. Généralement, ce logiciel permet de les visualiser sous forme de dashboards. Ils peuvent être customisés pour répondre à un besoin utilisateur. Par exemple, nous pouvons ajouter des graphes spécifiques à l’aide d’un langage de requêtes. Nous pouvons corréler les données issues des différents piliers pour comprendre l’origine d’une erreur en cas d’incident, ce qui facilite sa résolution.
AWS propose différentes briques pour aider à centraliser les données d’observabilité issues de différents composants ou services.
Le service proposé par défaut est CloudWatch. Il centralise les logs et les métriques.
Que ce soit une application déployée sur une instance EC2, dans un conteneur ou une lambda, il est possible de les récupérer ensuite dans CloudWatch. Il peut être nécessaire d’installer un agent CloudWatch pour collecter les logs. Concernant les lambda, les logs issus de la sortie console standard sont automatiquement envoyés vers CloudWatch. Il n’est pas nécessaire d’installer un agent particulier.
De même les métriques intéressantes sur la durée d’exécution de notre fonction ainsi que sa consommation mémoire sont aussi envoyées vers CloudWatch. Grâce à ces données, nous pouvons dimensionner correctement cette fonction afin de réduire les coûts associés.
CloudWatch propose des outils permettant de requêter et de visualiser sous forme de graphes les données d’observabilité avec le service CloudWatch Insight. Nous pouvons aussi ajouter des alarmes si une limite est atteinte afin d’être alertée ou de remédier automatiquement au problème.
En effet, nous pouvons positionner une alarme sur la latence constatée sur un Load Balancer. Si elle dépasse un certain seuil, cela veut dire que notre système commence à être chargé et n’est pas capable de répondre à la demande. Cette alarme est activée et déclenche l’ajout d’une instance dans le groupe d’instances pour réduire la latence.
Concernant les traces, nous devons utiliser un autre service appelé X-Ray.
Nous ajoutons alors le SDK X-Ray dans les dépendances de notre projet pour pouvoir annoter notre code. La librairie prend en charge l’envoi de nos traces applicatives vers le service X-Ray. De nombreux services AWS envoient aussi leurs traces directement à X-Ray. Par exemple, DynamoDB, API Gateway (de type REST uniquement, le type HTTP ne le prend pas en charge) etc. Pour les lambdas, il est nécessaire d’activer le service et d’importer par exemple le SDK sous forme d’une layer proposée par AWS.
AWS expérimente une nouvelle console où le service X-Ray est directement intégré à la console CloudWatch
AWS propose le Well Architected Framework qui est un ensemble de bonnes pratiques à mettre en œuvre pour déployer une infrastructure (qu’elle soit serverless ou non) sur son cloud. Différents piliers constituent ce framework et ils proposent aussi de bonnes pratiques sur la mise en œuvre et l’exploitation d’applications serverless.
Dans le document Serverless Application Lens - AWS Well-Architected Framework concernant l’excellence opérationnelle https://docs.aws.amazon.com/wellarchitected/latest/serverless-applications-lens/opex-metrics-and-alerts.html, AWS liste un ensemble de préconisations. Passons les en revues en fonction de chacun des piliers de l’observabilité.
Pour les métriques, AWS recommande d’utiliser le format EMF (Embedded Metric Format - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch_Embedded_Metric_Format_Generation.html. Ce qui permet aisément d’ajouter des métriques directement dans les fichiers de logs. Cloudwatch est alors capable de récupérer les métadonnées et les métriques associées en parsant les logs.
Les métriques sont alors disponibles sous forme de métriques personnalisées et peuvent être requêtées.
Voici un exemple de métrique au format EMF :
{
"LogGroup": "OrderLambdaFunction",
"ServiceName": "OrderLambdaFunction",
"ServiceType": "AWS::Lambda::Function",
"FunctionName": "OrderLambdaFunction",
"AccountId": "1234567890123",
"RequestId": "1f4fe4ba-f379-4da2-a6e9-39c1583ade6d",
"executionEnvironment": "AWS_Lambda_python3.9",
"memorySize": "256",
"functionVersion": "$LATEST",
"logStreamId": "2022/11/16/[$LATEST]dddec35e00e54aa4b903a2b50eeecacd",
"_aws": {
"Timestamp": 1668589503,
"CloudWatchMetrics": [
{
"Dimensions": [
["LogGroup", "ServiceName", "ServiceType", "FunctionName"]
],
"Metrics": [
{
"Name": "ProcessingLatency",
"Unit": "Seconds"
}
],
"Namespace": "aws-embedded-metrics"
}
]
},
"ProcessingLatency": 0.78322
}
La partie “_aws” permet de spécifier le nom des métriques personnalisées ainsi que leur unité.
A noter qu’AWS propose des librairies pour pouvoir générer ces métriques au bon format (disponible en Python, Java, Javascript et .Net).
Par défaut, les lambda écrivent les logs sur la sortie standard. Néanmoins, les logs réalisés avec les instructions python print ou javascript console.log sont difficiles à interpréter et à analyser.
AWS recommande de privilégier des fichiers journaux structurés au format JSON. Nous pouvons ajouter facilement des informations supplémentaires dans ce format. Une fois indexé, CloudWatch Insight permet de générer des métriques à partir d’une requête sur ces logs.
AWS préconise de mettre les correlations ID et de les passer aux services suivant pour pouvoir facilement suivre les traces entre les différents composants. De plus, si les fonctions lambdas sont fortement sollicitées, elles généreront une volumétrie importante de logs ce qui augmentera aussi le coût associé. Néanmoins, il peut être intéressant de garder des logs avec le niveau debug pour pouvoir facilement diagnostiquer un incident. Dans ce cas, nous pouvons configurer et spécifier d’avoir un pourcentage de logs en DEBUG parmi toutes les invocations.
Voici un log structuré au format JSON. Dans ce log, nous pouvons voir que le x_ray_trace_id est bien présent.
{
"timestamp": "2022-11-16 10:09:19,582",
"level": "INFO",
"location": "OrderLambdaFunction.handler:45",
"service": "Order",
"lambda_function_name": "OrderLambdaFunction-12DDCZH4QJ11T",
"lambda_function_memory_size": "256",
"function_arn": "arn:aws:lambda:us-east-1:1234567890123:function:OrderLambdaFunction-12DDCZH4QJ11T",
"lambda_function_request_id": "72bb1b4c-b770-4120-a0e5-598c1848d2b4",
"message": {
"customer_id": "5b537a52-3e47-4d2d-9ddb-706915cf3ca5",
"order_id": "7719c0f3-2e58-4ab3-bd4e-447770e1fcaf",
"text": "Order created with success."
},
"sampling_rate": 0,
"cold_start": true,
"xray_trace_id": "1-515912ef-12789f5810f89fd61bb81446"
}
AWS conseille d’activer le service X-Ray pour pouvoir suivre les traces entre les différents composants et d’activer les deux fonctionnalités suivantes:
Grâce à ces deux fonctionnalités, nous pouvons rapidement diagnostiquer le goulet d’étranglement lors d’un appel à notre API. Par exemple, est-ce la durée de la requête vers la base qui pose problème ou est-ce l’envoi d’un fichier vers une api externe.
Pour faciliter la mise en œuvre de ces recommandations, AWS propose un ensemble de librairies appelées lambda powertools. À ce jour, les librairies sont disponibles pour les langages Python, JavaScript / TypeScript, Java et .Net. En fonction du langage choisi, elles proposeront des fonctionnalités supplémentaires. Elles reposent sur un socle commun pour faciliter l’ajout de données d’observabilité dans nos fonctions lambda ou pour nos applications conteneurisées.
À noter que la librairie pour le langage Python est la plus avancée. Elle propose des fonctions pour définir le format des entrées et sorties de nos lambda, pour typer nos variables (fonctionnalité de Python 3.9), etc.
Quel que soit le langage supporté, cette librairie fournit ces trois utilitaires:
AWS propose une layer dans chacune des régions qui pourra être associée à notre lambda lors du déploiement.
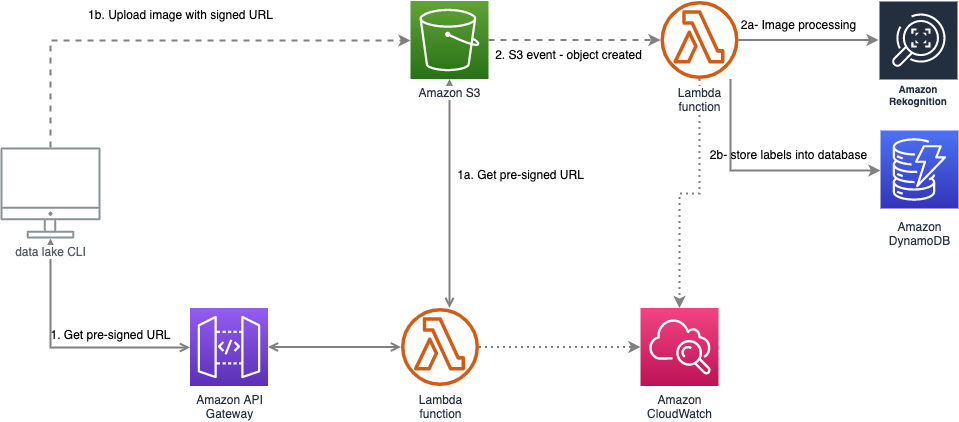
Pour démontrer la facilité de la mise en oeuvre, je vous propose une application distribuée écrite en python que vous trouverez sur mon dépôt github : https://github.com/ddrugeon/cat-detector
Cette application est composée de plusieurs lambdas qui interagissent avec une API gateway, une base DynamoDB, un bucket S3 et le service de reconnaissance d’images Rekognition.
L’application permet à un utilisateur d’ajouter une image sur un bucket S3. Pour sécuriser l’accès au bucket, une lambda génère une url pré-signée donnant le droit temporaire de copier cette image. À la création du fichier, une seconde lambda est automatiquement déclenchée. Celle-ci interroge le service Rekognition pour récupérer des informations sur ce qui a été détecté dans l’image. Ces informations seront ensuite stockées dans une table dynamodb.
Pour pouvoir utiliser la librairie, nous avons deux possibilités:
A noter, cette librairie est bien entendu disponible pour les architectures x86 comme arm64
Nous configurons la librairie en fonction de nos besoins et les services que nous voulons activer. Lors du déploiement, nous renseignons les valeurs des variables d’environnement. Les plus courantes sont
Bien entendu, nous pouvons surcharger au moment de la construction des objets les valeurs de ces variables.
Je vous convie à aller sur la page officielle de la librairie pour en savoir davantage sur les valeurs possibles.
Dans notre code applicatif, nous avons juste à déclarer les différents outils que nous voulons utiliser. Par exemple, dans le handler de la lambda du service image-processing (https://github.com/ddrugeon/cat-detector/blob/main/services/image-processing-service/src/handler.py), j’ai activé le logger et le tracer
...
from aws_lambda_powertools import Logger, Metrics, Tracer
from aws_lambda_powertools.metrics import MetricUnit
...
logger = Logger(log_uncaught_exceptions=True) (1)
tracer = Tracer()
metrics = Metrics()
...
@tracer.capture_method() (2)
def process_image(bucket_name: str, object_key: str) -> List[str]:
...
@tracer.capture_lambda_handler (3)
@logger.inject_lambda_context(correlation_id_path=correlation_paths.S3_OBJECT_LAMBDA,
log_event=True)
@metrics.log_metrics(capture_cold_start_metric=True)
@event_source(data_class=S3Event)
def process(event: S3Event, context: LambdaContext) -> dict:
bucket_name = event.bucket_name
logger.info(f'Receiving new file object to process from {bucket_name}')
...
metrics.add_metric(name="SuccessfulImageProcessing", unit=MetricUnit.Count, value=1)
(1) Le logger et le tracer doivent être des variables globales. Je conseille de les centraliser dans un seul fichier et de les créer en dehors de la fonction handler de la lambda
(2) Au niveau de chaque fonction ou méthode, nous ajoutons cette annotation pour indiquer au tracer de prendre en compte le temps d’exécution dans la fonction. Il créera un sous-segment associé.
(3) Au niveau de la fonction handler, nous ajoutons l’annotation tracer.capture_lambda_handler pour indiquer au tracer de prendre en compte cette fonction. Il récupèrera automatiquement le correlation id positionné par le runtime des lambdas. L’annotation logger.inject_lambda_context permet de récupérer le contexte d’exécution de la lambda (le type d’event peut être indiqué) et sera ajouté automatiquement aux différents messages.
En plus des classes relatives à l’observabilité, cette librairie propose des classes utilitaires permettant de mapper par exemple l’event avec un type particulier ce qui permet à votre IDE de proposer de l’autocomplétion. Il y a aussi des classes et fonctions pour ajouter de la validation sur vos paramètres d’entrées et de sorties de vos lambda.
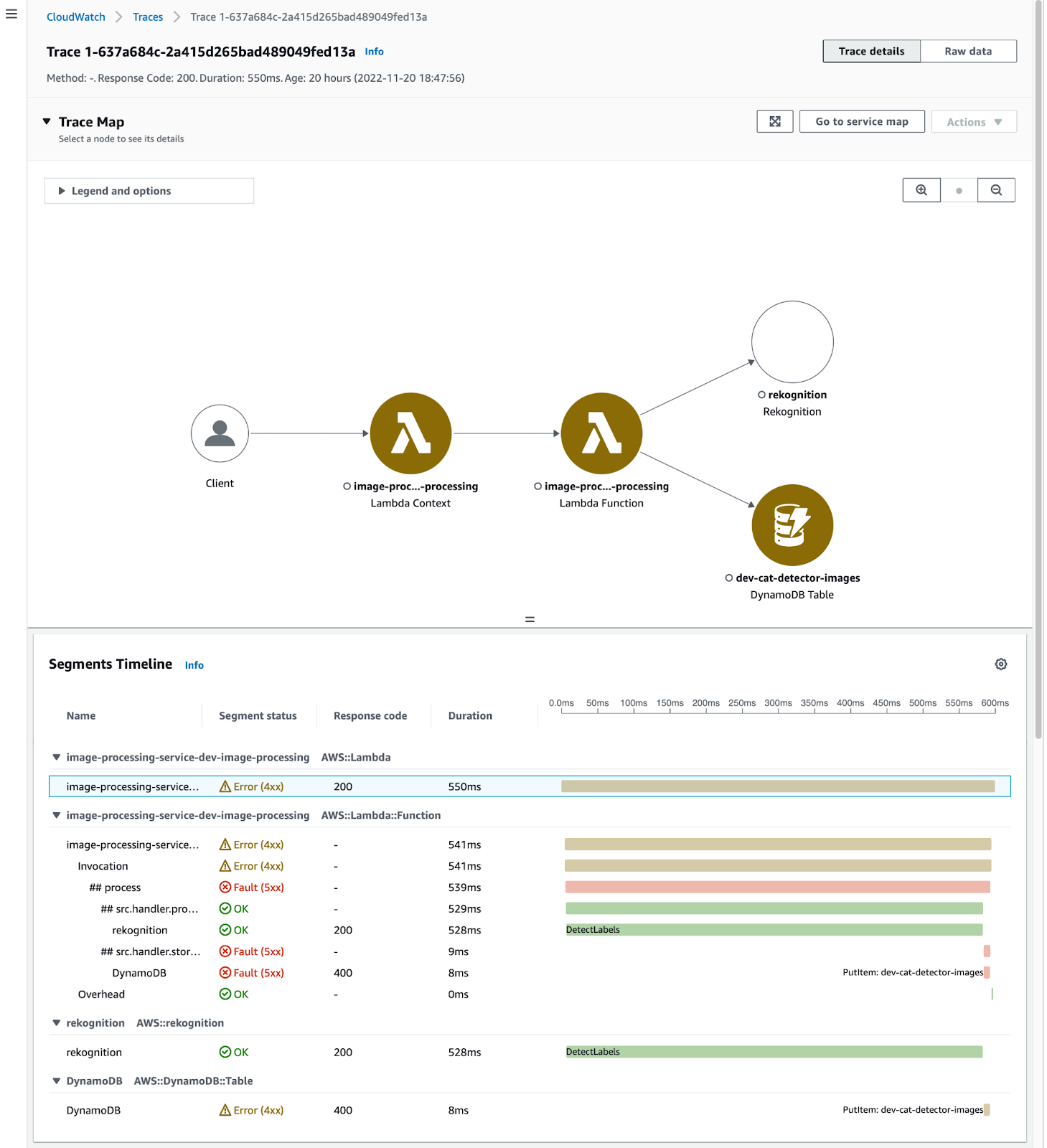
Sur la console AWS au niveau de notre fonction lambda, nous pouvons directement voir les métriques, logs et traces des dernières invocations. Pour avoir une vue plus globale, nous pouvons accéder directement aux traces, logs et métriques dans la console CloudWatch
Dans la capture suivante, nous pouvons voir qu’un service est en erreur et la lambda ne peut traiter la demande.
Nous pouvons aussi voir les logs associés et comprendre pourquoi il y a une erreur sur l’écriture de notre enregistrement en base de données:
Dans cet article, je vous ai introduit les notions d’observabilité de nos applications serverless. Sur notre blog, Jean-Pascal a déjà écrit un article complet sur l’observabilité. Je vous convie à le lire pour en comprendre ses enjeux. Et pourquoi c’est nécessaire dans nos architectures de plus en plus distribuées : https://blog.wescale.fr/quest-ce-que-lobservabilite.
Pour faciliter la mise en place de l’observabilité, je vous conseille de suivre le tutoriel proposé directement sur la page de la librairie : https://awslabs.github.io/aws-lambda-powertools-python/2.3.1/tutorial/
De plus, AWS propose un workshop dédié pour comprendre les différentes briques d’observabilité disponibles (basé sur des stacks open sources comme opentelemetry ou prometheus / graphana / loki et des stacks AWS) : https://catalog.workshops.aws/observability/en-US
Une série d’articles proposés par Ran Isenberg sur son blog permet d’avoir un aperçu des bonnes pratiques à adopter pour développer ses lambdas et entre autre propose la mise en place détaillée des données d’observabilité : https://www.ranthebuilder.cloud/post/aws-lambda-cookbook-elevate-your-handler-s-code-part-1-logging
Enfin, l’équipe developer advocate d’AWS propose à travers le blog du startup fictive ‘I love my local farmers’ les choix d’architecture, de refactoring de leur application. Un article explique comment ils ont ajouté cette librairie dans leur code Java pour faciliter le debogage de leur application: https://medium.com/i-love-my-local-farmer-engineering-blog/serverless-observability-made-easy-with-lambda-powertools-for-java-metrics-logging-863bed8c6310
Et n’oubliez pas de consulter nos formations Cloud Native sur notre site : https://training.wescale.fr/
Objectifs Il y a des modes en informatique et l’utilisation de “BuzzWord” est fréquente. Dans les derniers de ceux-ci, un terme revient souvent :...

Dans cet article nous allons mettre en place une fonction AWS Lambda pour exécuter des commandes sur une instance Linux EC2 via un appel API en...
