
6 minutes de lecture

La multiplication des clusters Kubernetes en vue d'orchestrer une flotte de conteneurs applicatifs en est le meilleur exemple. Dans ce contexte, comment pouvons-nous nous assurer que notre plateforme applicative va bien ? Qu’elle ne nécessite pas d’interventions pour continuer à délivrer la valeur pour laquelle elle est prévue ? En cas de problème, comment réaliser un diagnostic dans les plus brefs délais ?
A force de chercher des réponses à ces questions, un ensemble de concepts a émergé sous le nom d'Observabilité.
Les usages
L'Observabilité est un ensemble de données qui permet d'être exploité de différentes manières. La plus courante est la supervision via la mise en place de moniteurs et d’alertes.
Le moniteur est chargé de définir un état basé sur une ou plusieurs données d'Observabilité puis de challenger une assertion. Si les conditions sont réunies, le moniteur va déclencher une alerte. Cette alerte peut notifier des opérateurs, un gestionnaire d’incidents ou encore une plateforme d'auto-remédiation.
En se basant sur des données d’Observabilité, il est aussi possible de faciliter la planification de consommation des ressources en étant proactif. L’observabilité permet de constater qu’une partie de l’infrastructure va prochainement être en rupture et qu’il faut donc en provisionner de nouvelle.
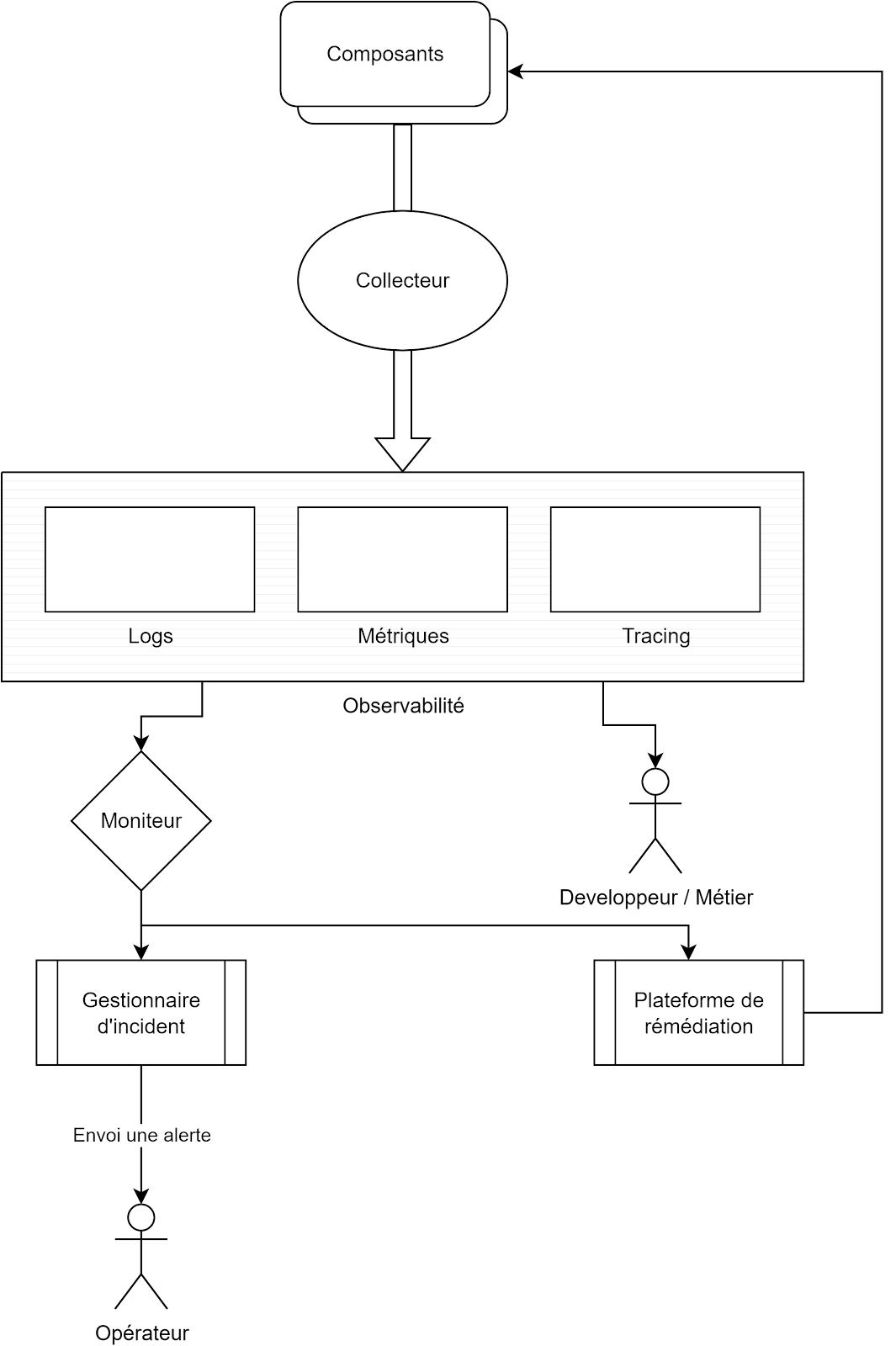
Les fondements de l'Observabilité
Une définition possible de l'Observabilité serait la suivante : l'Observabilité est la capacité d’un système à exposer des informations pouvant être exploitées afin de déterminer son fonctionnement et son état.
Cela implique, entre autres, que le système observable puisse continuer à fonctionner sans sa solution d'Observabilité.
Pour ce faire, nous pouvons classer les informations d'Observabilité dans 3 piliers.

La métrologie
Le plus simple des 3 piliers à appréhender est celui de la métrologie. Il s’agit d’un ensemble de données numériques historisables dans le temps, aussi appelées métriques. Ces données sont généralement stockées dans une base de données timeseries. Cela permet, par exemple, de calculer le temps qu’il reste à une machine avant de probablement avoir rempli son disque dur.
Les logs
Ce pilier est souvent le plus utilisé. C’est en effet le moyen historique des équipes applicatives et système pour diagnostiquer et déboguer une application. Les journaux sont une succession d'événements datés décrits par du texte.
Les traces
Les traces sont une représentation du parcours d’une interaction d’un acteur sur le système. L’acteur peut être un utilisateur ou une application. Une trace est constituée de spans qui représentent le passage d’une interaction utilisateur au sein d’un composant ou d’une fonction d’un composant. Nous pouvons donc trouver dans un span une date de début et de fin d'exécution.
Les traces peuvent être propagées d’un composant du système à un autre; nous parlons alors de tracing distribués.
Les Applications Performance Manager (APM), reposent sur l'utilisation de traces en les générant par introspection à votre place. Il est alors possible de savoir quelle fonction d’un composant prend le plus de temps dans l’interaction de l’acteur avec le système.
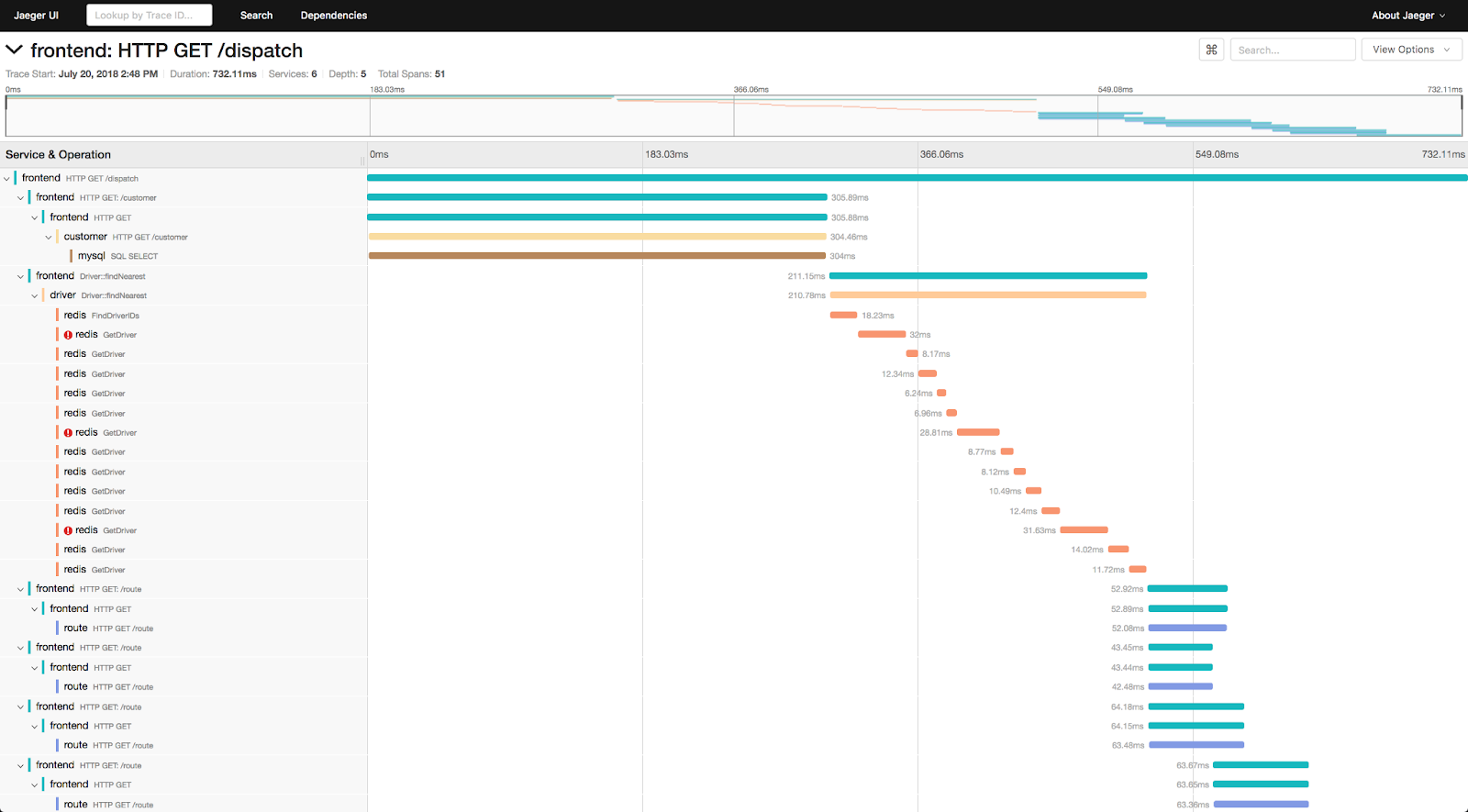
Exploiter les données d'Observabilité
En nous donnant de la visibilité sur l'état de nos systèmes, l'Observabilité nous permet de :
- réduire le temps de reprise sur incident
- rendre visibles les impacts des changements apportés au système
- autonomiser les parties prenantes au cycle de vie du système
Pour ce faire, il est nécessaire de désiloter l'accès aux données de l’Observabilité. Qu’il s’agisse de l'équipe chargée de la production, de l'équipe chargée de la réalisation ou encore des utilisateurs, il est important de donner à ces acteurs de votre système de la visibilité sur l'état des composants qu’ils utilisent.
Le gain est immédiat. Une équipe qui constate un dysfonctionnement de l’un de ses composants pourra vérifier les logs, y lire une trace d’erreur à la connexion à la base de données et aller consulter les métriques de ladite base sans avoir à demander une intervention de l'équipe de production ou des DBAs. Ils seront alors en mesure d’informer leurs utilisateurs. Les DBAs de leur côté pourront investiguer et solutionner le problème sans avoir à perdre du temps en communication à gérer.
Afin de qualifier quelles données d'Observabilité sont pertinentes pour la supervision, Google dans son livre sur le SRE décrit les 4 signaux d'or. Ces signaux sont :
- Les latences : le temps qu’un service prend pour répondre à une sollicitation
- Le trafic : le nombre de sollicitations simultanées auxquelles le service est soumis à un instant donné
- Les erreurs : tous les événements non prévus ou non gérés par le service
- La saturation : toutes données qui permettent de définir que le service ne sera plus en capacité de répondre, par exemple le taux de remplissage d’un disque dur
L’agriculture version Observabilité

Avant de pouvoir tirer parti des possibilités offertes par l'Observabilité, il est indispensable de collecter les données d'Observabilité et de les stocker. Une étape intermédiaire d’enrichissement de la donnée est possible, voire recommandée.
Il est important de comprendre que nous observons, nous ne savons pas forcément ce que nous cherchons à voir. Lorsque vous rentrez dans une pièce que vous ne connaissez pas, vos yeux ne cherchent pas un objet en particulier, vous allez regarder l’ensemble de la pièce et constater la présence d’une peinture verte, sentir une odeur d’encens, etc. Il est donc intéressant de collecter un maximum de données qu’il va falloir stocker dans une solution permettant la corrélation de toutes les données d'Observabilité. Pendant la découverte d’une pièce, vous faites appel à vos 5 sens et c’est bien le cerveau qui stocke ces informations et qui les corrèle pour analyse et en déduit que vous êtes entré dans un spa.
Le volume et la répartition de données d'Observabilité vont vous contraindre à considérer vos données comme un référentiel qu’il faut qualifier. Une bonne solution d'Observabilité vous permet de qualifier la donnée à l’aide d'étiquettes qui peuvent elles-mêmes faire appel à la mise en place d’une gouvernance.
Une bonne solution d'Observabilité ne doit pas être intrusive. Dit autrement, si la solution d'Observabilité devenait inopérante, elle ne devrait pas impacter les composants qu’elle observe. Ce n’est pas parce que le maître nageur n’est plus là pour me regarder que je coule.
Pour toutes les données d'Observabilité, il est possible de les catégoriser par niveau dans les couches du système.
L’infrastructure
Nous pouvons collecter ici tout ce qui touche à la couche basse du système d’information, comme les machines/VMs, équipements réseaux, datastores, etc.
La méthode de collecte peut être assez simple comme pour les machines/VMs. En effet, il est généralement possible d’installer un agent sur une machine qui collecte la consommation CPU/RAM, les IOs réseaux/disques, voire les processus.
Dans le cas d’appliances, comme beaucoup d'équipements réseaux, il est possible de collecter les données d'Observabilité via un journal d'événements et/ou du SNMP ou encore des APIs fournies par le composant.
Les middlewares
Cette catégorie représente tous les composants entre l’infrastructure et les applications, du HAProxy aux serveurs d’application JEE, en passant par vos clusters Kubernetes et vos bases de données. En fonction de la technologie observée, il peut être nécessaire de configurer votre agent de collecte avec des informations lui permettant de savoir comment faire son travail.
Les applications
Généralement, lorsque l’on pense aux données d'Observabilité applicatives, nous pensons rapidement aux logs, aux métriques d’une hypothétique JVM, du nombre de requêtes sur le service HTTP. Nous pouvons aussi y intégrer les données qui ont un sens pour le métier, comme le nombre de commandes dans les paniers pour un site de E-commerce.
L'Observabilité à construire comme un référentiel
La solution d'Observabilité peut rapidement collecter une quantité importante de données. Afin de faciliter la corrélation entre toutes ces données et en tirer partie, il est important de collecter et de stocker l'ensemble des données comme un référentiel. Une bonne pratique consiste à enrichir vos données d’Observabilité via des étiquettes (tag en anglais).
Afin de ne pas voir des données mal qualifiées, il est possible de mettre en place une politique de tags que vous pourrez partager avec l’ensemble des producteurs et consommateurs de l'observabilité.
Afin d’alimenter le référentiel des données d'Observabilité, n’hésitez pas à découpler la solution de collecte des services en eux-mêmes en vous appuyant sur des standards open source :
- les logs doivent être émis sur la sortie standard, de préférence au format JSON
- les métriques peuvent être mises à disposition en mode pull via un endpoint HTTP au format Prometheus ou OpenMetrics
- les traces peuvent être émises via OpenTelemetry et leur propagation via le standard W3C Http trace context
Les écueils à éviter
L'Observabilité et l’audit
Une bonne solution d’Observabilité permet de donner l’état de fonctionnement à l’ensemble des parties prenantes. Pour définir l’état d’un service, la solution choisie ne nécessite pas d’accéder à des données sensibles. Dans le cas d’une plateforme de E-commerce, elle n’a pas besoin de connaître le contenu des commandes des clients pour savoir si le service de paiement fonctionne correctement.
La solution d’Observabilité n’est pas une solution permettant de faire de l’audit, pour cela il existe des solutions de back office qui peuvent être spécifiques au service.
Les APMs comme solution d'Observabilité
Il existe de nombreux outils permettant de collecter et de stocker des données. Certains fournisseurs de solutions d’Observabilité mettent en avant leur APM.
Les APM, pour Application Performance Management, sont des outils qui vont instrumentaliser du code ou des composants de votre SI pour collecter des données d'Observabilité, essentiellement des traces. Ils répondent à des besoins liés à l'analyse des performances de votre service. Les APM ne sont pas de bons outils pour les besoins liés à l'Observabilité pour plusieurs raisons :
- l’APM va généralement devoir changer le comportement du code délivré, vous pouvez donc oublier le livrable unique et reproductible sur tous vos environnements
- l’APM va capturer pour vous beaucoup de données y compris des données potentiellement sensibles
- les APMs sont généralement fortement intrusifs sur vos services. Si un jour vous désirez changer de solution, vous allez impacter tous vos services.
Conclusion
L’Observabilité permet de donner de la visibilité sur l'état de l’ensemble d’un SI à toutes les parties prenantes, du développeur aux éventuels utilisateurs. Il est important de considérer la collecte et le stockage des données comme un référentiel. Certains standards commencent à émerger, il ne faut pas hésiter à s’appuyer dessus tout en étant le moins intrusif possible.
Avec une bonne maturité, toute une équipe produit peut voir en direct les impacts de ses livraisons sur les performances fonctionnelles de la plateforme, une équipe SRE pourra mesurer l'efficacité de ses actions ou réaliser des scénarios de Chaos Engineering. Le plus difficile restant de mettre sous Observabilité tout le SI.


Trivy, un scanner de sécurité couteau suisse
Trivy, principes et objectif Trivy (prononcé “trivi”) est un scanner de sécurité Open Source développé par Aqua Security. Il est exploitable en CLI,...