 Bastien Cadiot
Bastien Cadiot


Maintenant que nos déploiements sont performants, il s’agit de s’intéresser au stockage des données. Plusieurs types de stockage dans le cloud existent, nous allons aujourd’hui faire un focus sur le stockage objet Google Cloud Storage (GCS).
Débuter avec Google Cloud Storage
Commençons par étudier les bases, voir comment fonctionne GCS, et comment y accéder.
Concepts
En matière de stockage objet, il y a quelques concepts de base à connaître afin de bien comprendre l'ensemble.
Tout d’abord, tout est rangé dans un bucket, ce dernier est la base de tout notre stockage. Ce bucket est localisé géographiquement dans une région ou dans un emplacement multi-régional. Un élément important à noter est que le nom de chaque bucket doit être unique dans toute l'infrastructure mondiale Google Cloud ! N'espérez donc pas créer un bucket “test” ou “prod” ils sont probablement déjà utilisés !
Dans chaque bucket les objets sont virtuellement rangés dans une arborescence. Virtuellement car le nom d’un fichier n’a, en réalité, pas d’importance, seul son chemin complet (ou clé) constitue le nom réel du fichier. Ainsi, même si vous envoyez un fichier archive.zip dans un sous dossier temp, la réelle clé d'accès sera temp/archive.zip.
Chaque objet dans GCS conserve son arborescence et les seuls moyens d’accès sont par le biais de requêtes http : GET / POST / DELETE / etc… Cela signifie donc qu’il n’est pas possible de réaliser toutes les actions disponibles sur un système de fichiers classique. Il faut garder cela en tête quand on commence à utiliser le stockage objet. La modification d’un objet revient à le supprimer et à en renvoyer une nouvelle version.
Les utilitaires de gestion
Plusieurs méthodes existent pour manipuler Storage, celle de base est l’API HTTP directement. Ceci étant ce n'est la plus simple à utiliser, c’est pourquoi des interfaces existent : les SDK des langages supportés, la vue web depuis la console, et l’outil en ligne de commande gsutil. Nous allons utiliser ces deux derniers.
Gsutil s'installe simplement sur votre système en suivant la documentation. Si vous utilisez déja le SDK GCloud alors gsutil est probablement déja installé. Ensuite, les commandes peuvent être directement utilisées :
# Créer un bucket multirégional en Europe
gsutil mb -l eu gs://my-bucket
# Lister les buckets
gsutil ls
# Pousser un objet dans un bucket
gsutil cp test.conf gs://my-bucket/my-folder/
# Lister le contenu du bucket nouvellement créé
gsutil ls gs://my-bucket
# Récupérer plusieurs objets et l’arborescence
gsutil cp -r gs://my-bucket/* .
Choisir sa classe de stockage
Le stockage GCS est unifié, cela signifie qu’il est accessible partout de la même manière indépendamment de la réalité du stockage derrière. C’est justement cette réalité dont nous allons parler.
Quatre types de classe de stockage existent, et chacun a des attributs particuliers à garder à l’esprit lors du choix. Chaque bucket aura une classe de stockage par défaut, ainsi tous les objets créés à l’intérieur du bucket appartiendront à cette classe, cependant il est possible pour chaque objet de changer sa classe individuellement.
Les classes sont les suivantes :
- Régional : Cette classe correspond à l’usage le plus courant, elle est adaptée à la donnée chaude (Hot Data) et la facturation se fait sur la volumétrie stockée. Le bucket est localisé dans une seule région et la disponibilité est de 99,9%.
- Multi-régional : Le cas d’usage est très similaire à celui du bucket régional, la différence est liée à la disponibilité à 99,95%. Ce type de bucket, plus cher, permet de survivre à la perte d’une région entière. Le bucket sera affecté à un ensemble géographique : Europe, US, Asie. Attention il n’est pas possible de convertir un bucket régional en multi-régional, et inversement.
- Nearline : La classe correspond à des données dites “tièdes" (Warm Data), la disponibilité est de 99%. Le prix est réduit, et permet d’y placer des données accédées peu fréquemment, idéalement pas plus d’un accès tous les 30 jours. Attention : l’accès aux données est payant, et la suppression des données moins de 30 jours après leur écriture est facturée.
- Coldline : Cette dernière classe correspond aux données “froides” (Cold Data), le prix est largement réduit et est adapté à l'archivage, la disponibilité est de 99%. Il est conseillé d’y placer les données accédées une fois par an. Comme pour le nearline, l'accès est payant, et la suppression anticipée sous la barre des 90 jours est facturée également.
Quand on parle de SLA, attention à bien distinguer disponibilité (accès aux données) et durabilité (stockage des données). Le SLA annoncé de toutes les classes concerne la disponibilité mais la durabilité est, elle, bien plus élevée. Celle-ci est la même pour toutes les classes de stockage, et est de 99.999999999%. Un formateur de Google a fait une comparaison très pertinente avec les banques : si votre agence est fermée la nuit vous ne pouvez pas accéder à votre argent mais il continue à exister.
Le temps d’accès aux données reste identique peu importe la classe, même pour le coldline.
Automatiser le cycle de vie des objets
Lors du dépôt d’objets, soit vous savez déjà dans quelle classe les placer, soit ces objets peuvent vivre et devenir obsolètes au fil du temps. C’est typiquement le cas des journaux ou des fichiers temporaires. Dans ce cas, vous pouvez avoir besoin de les considérer comme HotData au début, puis ils deviennent par la suite des Warm voire des Cold Data.
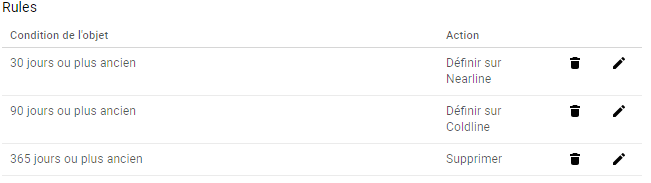
Dans ce cas de figure il n’est pas nécessaire de se soucier de ce cycle de vie, Google Cloud Storage peut l'automatiser pour vous. Il est possible d'appliquer des politiques réalisant la transition de classe automatiquement suivant l’ancienneté des objets. Ainsi, on peut décider que tous les objets de plus de 30 jours passent spontanément en Nearline, puis au-delà 90 jours en Coldline. Enfin, on peut même décider de les supprimer automatiquement.
Par exemple cela nous donnerait les instructions suivantes :
cat > lifecycle.json <<EOF
{
"rule": [
{
"action": {"storageClass": "NEARLINE", "type": "SetStorageClass"},
"condition": {"age": 30}
}, {
"action": {"storageClass": "COLDLINE", "type": "SetStorageClass"},
"condition": {"age": 90}
}, {
"action": {"type": "Delete"}, "condition": {"age": 365}
}
]
}
EOF
$ gsutil lifecycle set lifecycle.json gs://my-bucket/
Protéger les accès aux données
Toutes les données ont besoin d’être protégées, et le stockage objet ne déroge pas à la règle.
Le chiffrement des données
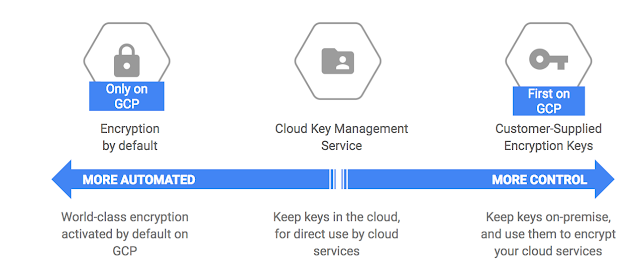
Sur GCS le chiffrement est automatique et non optionnel. Par défaut, les données sont chiffrées avec les clés de Google, mais peut-être avez-vous besoin de gérer vos clés vous-même ?
Pour cela, deux solutions alternatives existent :
- Utiliser le service de gestion des clés Google KMS, cela implique que votre application gère le chiffrement et le déchiffrement. Il s’agit d’un chiffrement côté “client”, GCS n’a pas connaissance que vos données sont chiffrées.
- Fournir les clés de chiffrement à GCS, ainsi le chiffrement sera réalisé directement côté serveur avec ces clés. Cependant, cette solution peut poser problème lors de l’utilisation de pipeline de données ne supportant pas cette méthode de chiffrement (par exemple l’intégration avec Dataflow n’est pas possible).
Dans le cas du service KMS, les clés de chiffrement et de déchiffrement restent gérées par Google, et vous devez vous assurer que chaque service que vous utilisez dispose bien des permissions d'accès à la clé KMS avant de tenter de lire les données sur GCS. Malheureusement il n’y a pas encore d’intégration KMS directement sur le stockage, tout le chiffrement est fait côté client.
Si vous préférez fournir vous-même la clé de chiffrement, dans ce cas vous seul gérez manuellement les clés, et vous êtes responsable de les faire parvenir aux services en ayant besoin. Dans ce cas le chiffrement se fait côté serveur, mais vous êtes seul responsable des clés et de la rotation. De même si vous les perdez, l’accès aux donnés sera irrémédiablement perdu.
Bien entendu si vous utilisez le mode par défaut Google Cloud se charge automatiquement de gérer toute cette partie chiffrement.
Le schéma suivant disponible sur le blog de google donne un bon aperçu des différentes possibilités de chiffrement.
Gérer les permissions
Les permissions utilisent exactement les mêmes mécanismes que le reste des ressources GCP, il est donc possible d’utiliser le système IAM pour autoriser les utilisateurs et/ou comptes de services.
Par défaut, les comptes autorisés GCS sur le projet obtiennent par héritage les droits équivalents sur le bucket, mais il est possible de changer cela et d’en ajouter de nouveaux.
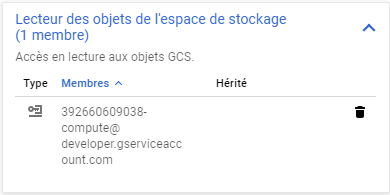
Par exemple si l’on souhaite ajouter un compte de service spécifique ayant un simple accès en lecture seule au bucket, on peut passer par la console ou utiliser la commande suivante (on utilisera la sous-commande ch pour ne pas écraser la configuration existante) :
gsutil iam ch serviceAccount:397660609030-compute@developer.gserviceaccount.com:objectViewer gs://my-bucket/
Ouvrir l’accès public aux objets
Après avoir vu les permissions, qu’en est-il des accès vraiment publics aux objets ? Si l’on souhaite donner accès sans avoir besoin de s'authentifier ?
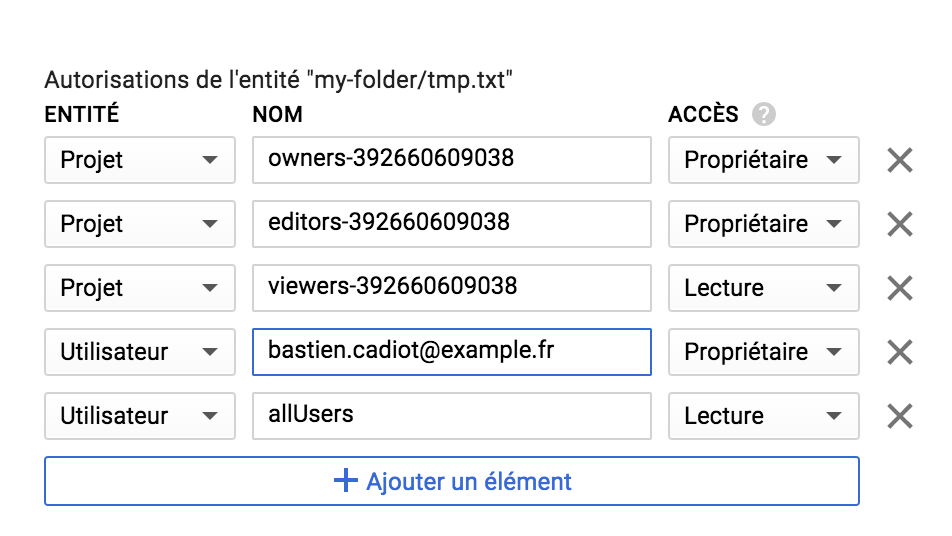
Si tout internet doit y avoir accès alors il est possible de rendre un objet public, ainsi son URL publique sera disponible et le simple fait d’y accéder permettra de lire son contenu. Cela est très pratique pour gérer un site internet statique, servir de cache, ou simplement mettre à disposition une archive.
Essayez d’y accéder via l’url suivante : https://storage.googleapis.com/my-bucket/my-folder/tmp.txt
Une méthode plus fine pour gérer les permissions est d’utiliser les ACLs, ce qui permet de définir des permissions par objet. En général il est préférable d’utiliser les permissions IAM, y compris pour les permissions relatives à l’ensemble des objets. Les ACLs ne seront utilisées que pour le réglage précis des permissions sur des objets spécifiques.
$ gsutil acl ch -u AllUsers:R gs://my-bucket/my-folder/tmp.txt
Updated ACL on gs://my-bucket/my-folder/tmp.txt
En parlant de mise à disposition d'archive, comment contrôler que le lien mis à disposition ne sera pas détourné ? Une fonctionnalité existe et permet de “signer les URL", ainsi, un lien temporaire est fourni et ce dernier ne fonctionnera que pour un nombre déterminé de téléchargements.
Pour aller plus loin
Nous avons parcouru certaines fonctionnalités parmi les plus utilisées de Google Cloud Storage. Avant de vous laisser, j’aimerais vous parler d’une dernière possibilité qui nous sera très utile dans un futur proche : les notifications.
Les notifications permettent de déclencher des évènements lors d'actions dans un bucket. Typiquement, on peut envisager de créer une notification à chaque fois qu’un objet est déposé dans un bucket. Ce type de mécanisme est une des bases des architectures “full cloud” car cela permet de lier les composants Cloud entre eux. Grâce à ces mécanismes nous pouvons utiliser GCS comme épine dorsale d’une solution Big Data.
Si vous souhaitez aller plus loin dans l’exploration de GCS, je vous invite à parcourir la documentation officielle très complète.
Conclusion
Le stockage objet sur Google Cloud n’a plus de secret pour vous, restez connectés pour en savoir plus sur Google Cloud ! Le code de nos exemples est disponible sur GitHub : https://github.com/bcadiot/gcp-from-scratch.
Vous avez des questions ? Vous voulez plus de détails ? N’hésitez pas à le dire dans les commentaires de l’article ou via Twitter.
À très vite pour la suite de notre découverte de Google Cloud. Pour le prochain article je vous propose de parler conteneurs dans le cloud !
Prometheus Starter Kit
Description Prometheus est une solution open-source (Apache 2.0) de monitoring et d’alerting développée à l’origine chez SoundCloud. Il a été le...

Valider statiquement son code Terraform
Préambule Dans notre métier, il est une bonne pratique d’utiliser de l’Infrastructure as Code et il n’est pas rare de faire le choix d’utiliser ...