Tutoriel : Infastructure résiliente et scalable avec Swarm, Consul et Traefik
Problématique Mettre en oeuvre une infrastructure scalable, résiliente et tout automatisée est devenu depuis quelques années le Graal de...
7 minutes de lecture
Nous avons vu dans la première partie du guide du Chaos Engineering (CE) que le CE ne peut pas avoir lieu sans expérimentations.
Nous allons continuer notre voyage fantastique dans ce monde en passant par le pays du "Chaos Tools Country".
Dans cette partie de l’histoire, je vais vous parler des outils de Chaos Engineering, très nombreux aujourd’hui. On peut les différencier selon un certain nombre de critères :
Les tests de chaos diffèrent d'un environnement à un autre : machines virtuelles, conteneurs (Docker, Kubernetes, OpenShift...), cloud (Openstack, Azure, AWS, GCP...).
Avant de commencer les tests avancés sur les systèmes, on peut effectuer quelques expérimentations simples de chaos. Comme on dit, on commence petit:
On sait que les ressources des machines virtuelles et des conteneurs sont limitées. Ces hosts peuvent atteindre le seuil de leur capacité à un moment donné. Dans ce cas, le système doit gérer l'absence de ressources (CPU, RAM...).
Alors, on peut créer des scripts pour engendrer l'épuisement du processeur. Ce test consiste à consommer des cycles de processeurs, laissant l'application avec le même nombre de tâches en relation avec le client et moins de CPU/RAM pour les faire.
Les réactions courantes de l'épuisement du processeur sont une augmentation des erreurs, de la latence donc une réduction des demandes réussies des clients. Dans ce cas, on obtient "unexpected fallback behaviour".
La gestion de la relation entre les applications et les bases de données est importante pour assurer le bon fonctionnement du système. Il existe plusieurs méthodes pour stresser cette relation en envoyant par exemple des requêtes médiocres, remplissant le cache et injectant de la latence dans les sources de données.
On pourra utiliser des commandes comme:dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &
cette commande permet de convertir et copier des fichiers.
Comme on sait que tout système distribué est caractérisé par des dépendances réseaux, ces dernières permettent la connexion entre les applications. Elles peuvent être internes ou externes. Là, on peut commencer par injecter de la latence réseau en utilisant tc:tc qdisc add dev eth0 root netem delay 50ms
et parmi les bonnes pratiques de chaos engineering qu’on doit connaitre comment revenir à l’état stable d’ou:tc qdisc del dev etho root netem delay 50ms
cette commande permet de contrôler le trafic réseaux.
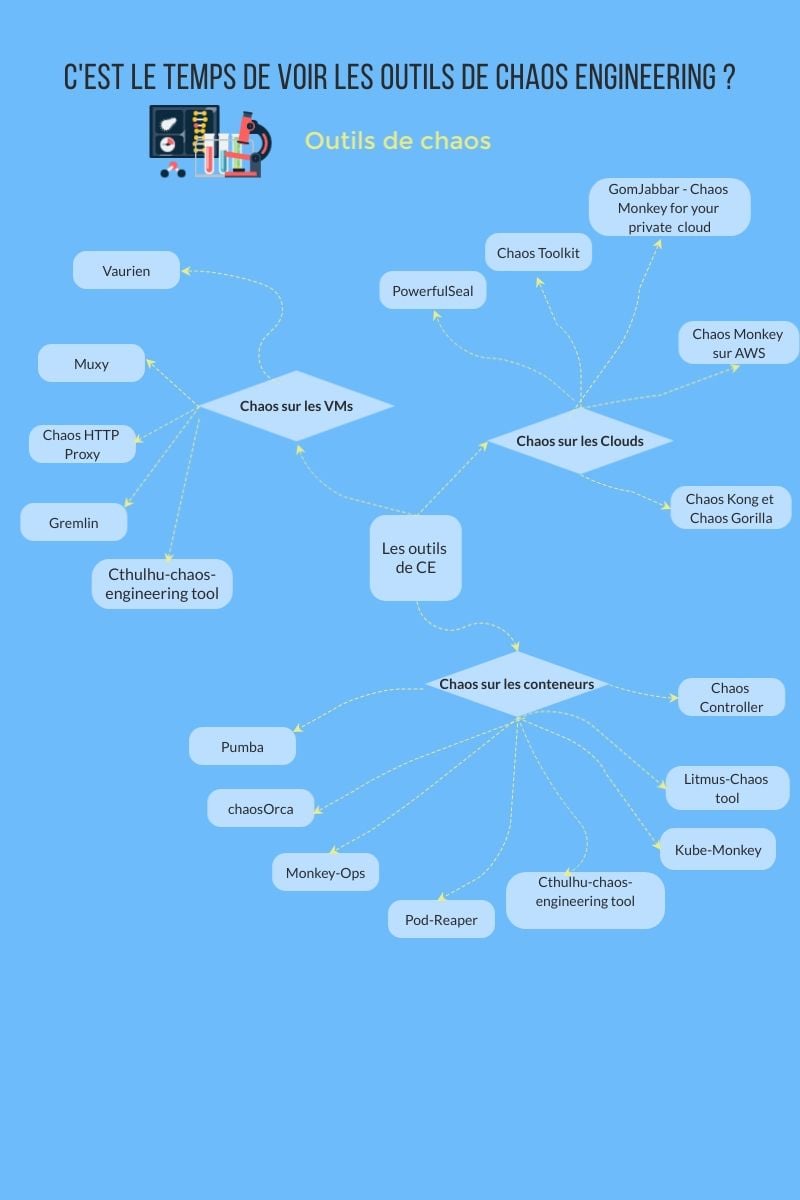
Les outils existants (les plus utilisés)
La communauté du Chaos Engineering est très active. Chaque jour, on trouve de nouveaux outils créés par cette communauté.
Je vais citer les outils les plus utilisés sur les machines virtuelles, conteneurs et cloud providers dont certains sont bien expliqués à la suite :
Dans cette partie, je vais parler des différents outils que j'utilise pour créer du chaos sur une architecture distribuée de micro-services implémentée sur machines virtuelles et Openshift, en commençant par VMs :
Vaurien est caractérisé par une classe appelée Behaviors, qui est invoquée à chaque fois qu'il s'exécute sur une requête. Par l'intermédiaire de cette classe, on pourra modifier le comportement du proxy, par exemple, en ajoutant de la latence au niveau d'une requête.
Les protocoles et Behaviors sont des plugins de Vaurien qui permettent d'en ajouter d'autres. En outre, Vaurien expose des APIs pour changer le Behavior du proxy.
On commence par exemple par ajouter une latence par cette API et on regarde comment l'application web réagit.
Il s'agit d'un outil open source pour créer du chaos uniquement sur des containers Docker (latence, kill, pause...).
C’est une plateforme de "Resilience As A service", qui peut générer plusieurs attaques de chaos. Elle permet de créer des templates d'attaques et de voir les rapports de ces attaques.
Kaos (Kinda Chaos Monkey for Kubernetes) : il s'agit d'un outil open source qui est compatible seulement avec Kubernetes. Il est basé sur CRD (Custom Resource Definition).
Kube-monkey : il s'agit d'un outil open source, c’est une implémentation de Chaos Monkey de Netflix pour les clusters Kubernetes. Il est développé avec le client-go v7.0 de Kubernetes. Il supprime aléatoirement des pods dans un cluster. Il est exécuté à une date pré-configurée et il crée un plan horaire de déploiements qui vont perdre des pods. Il peut être configuré avec une liste de namespaces, par exemple : blacklisted namespace, c'est-à-dire qu’aucun déploiement dans ce namespace ne sera affecté. Pour pouvoir exécuter Kube-monkey sur des Kubernetes apps, ll faut positionner des labels sur les applications Kubernetes tels que : kube-monkey/enables, kube-monkey/mtbf, kube-monkey/identifier, kube-monkey/kill-mode.
Monkey-ops : il est utilisé avec Openshift 3.X. Son rôle est de jouer aléatoirement avec les pods et deployment Config (supprime des pods et scale-up and down les dcs).
Quels sont les facteurs à avoir en tête pour implémenter du chaos sur des VMs et Kubernetes :
VMs
Kubernetes
/var/run/docker.sock. En effet, l'accès sur /var/run/docker.sock se fait par le root sur les hosts où le Docker Engine est installé. Cela permet aussi à Pumba de pouvoir interagir avec l’ensemble des containers démarrés sur cet hôte, que ce soit pour les piloter, ou se connecter dessus.Par exemple, on peut injecter de la latence dans un cluster Kubernetes en utilisant PUMBA:
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: pumba
spec:
template:
metadata:
labels:
app: pumba
name: pumba
spec:
containers:
- image: docker-registry.default.svc:5000/dvs-devops-groupe-none-hors-prod/pumba:master
imagePullPolicy: Always
name: pumba
command: ["pumba"]
args: ["--random", "--debug", "--interval", "30s", "kill", "--signal", "SIGKILL", "re2:.*hello.*"]
securityContext:
runAsUser: 0
volumeMounts:
- name: dockersocket
mountPath: /var/run/docker.sock
volumes:
- hostPath:
path: /var/run/docker.sock
name: dockersocket
Pour rappel et comme expliqué plus haut l’utilisation de pumba crée des failles de sécurité.
Après cette lecture, vous aurez pu remarquer que les outils de CE sont très nombreux. Le choix de ces derniers dépend de plusieurs paramètres, de vos besoins, par exemple vous n’utiliserez pas les mêmes pour Kubernetes ou des VMs.
La troisième partie de ce guide est en cours d’écriture, on vous y présentera une démo de chaos engineering. Stay tuned!
Des liens utiles:
Chaos sur les VMs :
On peut utiliser les scripts : saturation du disque, latence au niveau réseau, charge sur les CPUs.
Chaos sur les containers :
Chaos sur les clouds :
Problématique Mettre en oeuvre une infrastructure scalable, résiliente et tout automatisée est devenu depuis quelques années le Graal de...
Une solution que j’affectionne particulièrement est Traefik, car elle est simple à prendre en mains et propose suffisamment d’options pour ce que je...
