
15 minutes de lecture

Cet article sous forme de hands-on lab est fait pour que vous puissiez dérouler les expérimentations vous même. Il contient tout ce dont vous aurez besoin comme étapes, de l’installation du cluster GKE (Google Kubernetes Engine) à la création d’expérimentations en passant par le déploiement d’une application-sujet pour vos expériences. Vous pouvez lire cet article pour vous acclimater au sujet et anticiper les étapes mais nous vous recommandons de prévoir un peu de temps devant vous si vous voulez suivre le lab.
Pré requis pour le lab
- Un compte GCP
- Terraform >= 0.13
- Un cluster Kubernetes >= 1.15
- Une soif de destruction :)
Notez que ce lab est prévu sur Google Cloud Platform et que la création de ressources engendre naturellement des coûts. Pour minimiser ces coûts, si vous êtes un peu plus familier avec les pré requis, vous pouvez également adapter le lab pour faire déployer cette infrastructure en local sur votre machine avec des solutions comme minikube et KinD.
Glossaire
Pour commencer, un peu de vocabulaire pour se familiariser avec le Chaos Engineering et l’écosystème Litmus :
Chaos Engineering (CE) : Discipline d’expérimentation dans les systèmes complexes et distribués, qui vise à s’assurer de leur comportement face à des incidents et perturbations.
Chaos Hub : Répertoire qui contient les différentes expérimentations de Chaos.
Google Cloud Platform (GCP) : Provider cloud public de Google.
Experiment (fr: expérimentation) : Représente et décrit le test de Chaos à implémenter.
Litmus : Outil de Chaos Engineering open-source sur Kubernetes et qui fait partie des outils de la CNCF.
GitOps : Concept d’implémentation du déploiement continue pour les applications cloud-natives.
Argo CD : Outil de livraison continue GitOps pour Kubernetes.
Reliability score: Score attribué à chaque expérimentation d’un workflow Litmus. En fonction de la réussite ou de l’échec de chaque expérimentation, il permet d’obtenir une note de fiabilité du workflow.
Sock-shop: Site de démonstration créé par WeaveWorks
Rappel : qu’est-ce que le Chaos Engineering ?
Le Chaos Engineering (CE) est une discipline d’expérimentation dans les systèmes complexes et distribués, qui vise à s’assurer de leur comportement face à des incidents et perturbations. On pourrait définir de manière poétique le CE tel que “apporter l’harmonie par le chaos”. En effet, la solution la plus simple et efficace pour attester de la résilience d’un système, c'est de voir si on peut le casser. Au travers de cette discipline, nous souhaitons prouver par la pratique que notre cluster Kubernetes est capable de surmonter un traumatisme contrôlé.
La notion de Chaos est aussi importante à clarifier. En réalisant des activités destructrices et perturbantes au sein de nos clusters, l’état de celui-ci n’est plus stable, il est dans un état dit “chaotique”. Cela ne veut pas dire qu’il n’est plus en état de fonctionner, c'est même, au contraire, ce que nous souhaitons vérifier. En revanche, si cette instabilité provoque une indisponibilité des services, alors cela prouvera que notre infrastructure n’est pas résiliente.
Pour découvrir plus en détail ce qu’est le Chaos Engineering, nous vous invitons à lire ces articles sur le sujet rédigés par Akram Riahi :
- https://blog.wescale.fr/2019/09/26/le-guide-de-chaos-engineering-part-1/
- https://blog.wescale.fr/2020/03/19/le-guide-de-chaos-engineering-partie-2/
Ou à l’écouter :
Litmus
Qu’est-ce c’est?
Litmus est un outil de Chaos Engineering cloud native pour Kubernetes sous licence Apache 2.0. Il fournit des outils pour orchestrer le Chaos au sein de vos clusters Kubernetes, afin de vous assurer de la résilience de vos déploiements. Vous pouvez l’utiliser pour exécuter différents scénarios catastrophes au sein de vos environnements.
Pourquoi utiliser Litmus ?
Maintenant que nous en savons un peu plus sur Litmus, nous sommes en droit de nous demander l’intérêt de cette solution et de l’implémentation de la pratique Chaos au sein de nos infrastructures. Litmus apporte plusieurs avantages :
- trouver des défauts dans vos clusters et applications Kubernetes ;
- expérimenter le Chaos plus facilement, dans la rédaction, l’exécution et l’adaptation aux applications ;
- avoir un portail web esthétique, visuel, intuitif et qui permet de gérer les utilisateurs et autorisations associés ;
- permettre de créer, gérer et surveiller le Chaos au sein de vos clusters Kubernetes.
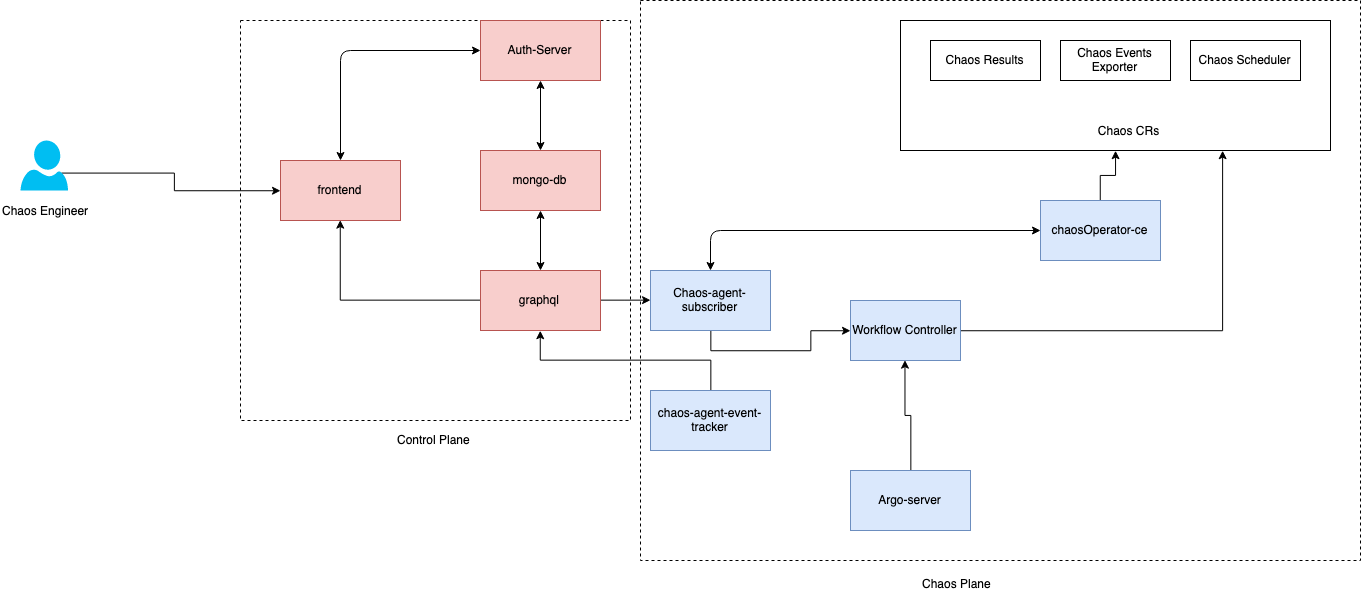
Architecture de Litmus
Litmus prend une approche cloud native pour créer, générer et surveiller le Chaos. Pour générer ce Chaos contrôlé, Litmus utilise plusieurs Custom Resource Definitions (CRD) au sein du cluster Kubernetes. L’architecture interne de Litmus est composée de nombreuses briques qui interagissent entre elles, voici les principales :
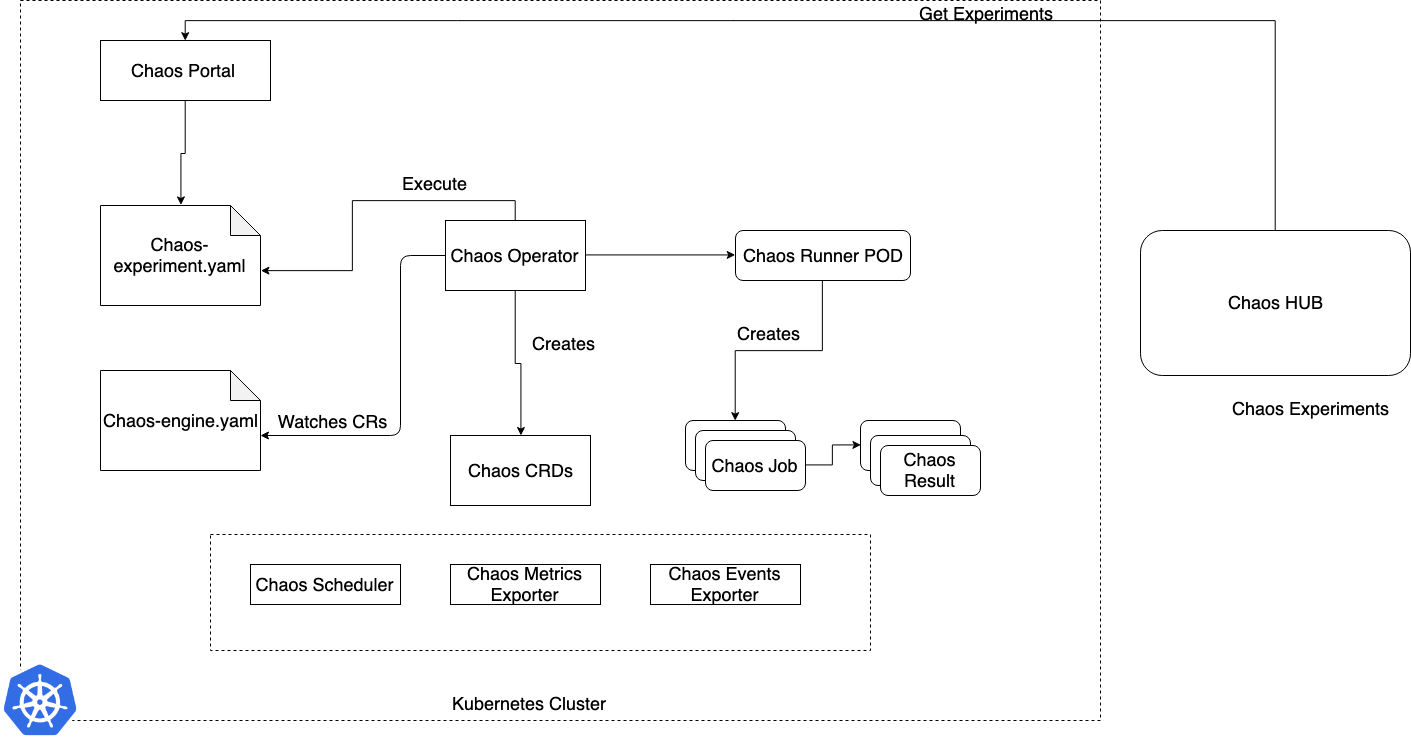
- ChaosEngine : cette ressource permet de lier une application Kubernetes ou un nœud à un ChaosExperiment. C’est cette brique qui organise la façon dont est exécutée une expérimentation. Le ChaosEngine est chargé de l’exécuter.
- ChaosExperiment : cette ressource permet de regrouper les paramètres de configuration d’une expérimentation de Chaos. Des CR (Custom Resource) Kubernetes sont créées (concrètement des pods) par le ChaosExperiment à chaque fois qu’une expérimentation est invoquée par le ChaosEngine.
- ChaosResult : cette ressource retient les résultats d’une expérimentation de Chaos. Le résultat est créé et mis à jour au moment de l’exécution par l’expérimentation elle-même. C’est cette brique qui retient les informations telles que la référence du ChaosEngine, l’état de l’expérimentation, le résultat de l’expérimentation, etc. Elle est la source de la collection de métriques. Le Chaos-exporter lit les résultats et les exports vers un serveur Prometheus préconfiguré.
- ChaosScheduler : cette brique s’occupe de programmer les différentes expérimentations de Chaos. ChaosScheduler invoque le ChaosEngine pour déclencher un test programmé.
Litmus met à disposition de ses utilisateurs d’autres briques optionnelles :
- Litmus Probe : sonde de contrôle que vous pouvez ajouter à vos expérimentations de Chaos. Litmus exploite les métriques de résultat pour offrir un verdict sur la réussite ou non de l’expérimentation, en plus des autres vérifications standards.
- Chaos portal : il s'agit d'un portail Web centralisé pour la création, la planification et la surveillance des flux de travail du Chaos. Le portail Litmus simplifie l'expérience d'ingénierie du Chaos pour les utilisateurs.
Dans le diagramme ci-dessous, nous détaillons le Workflow de l’expérimentation :
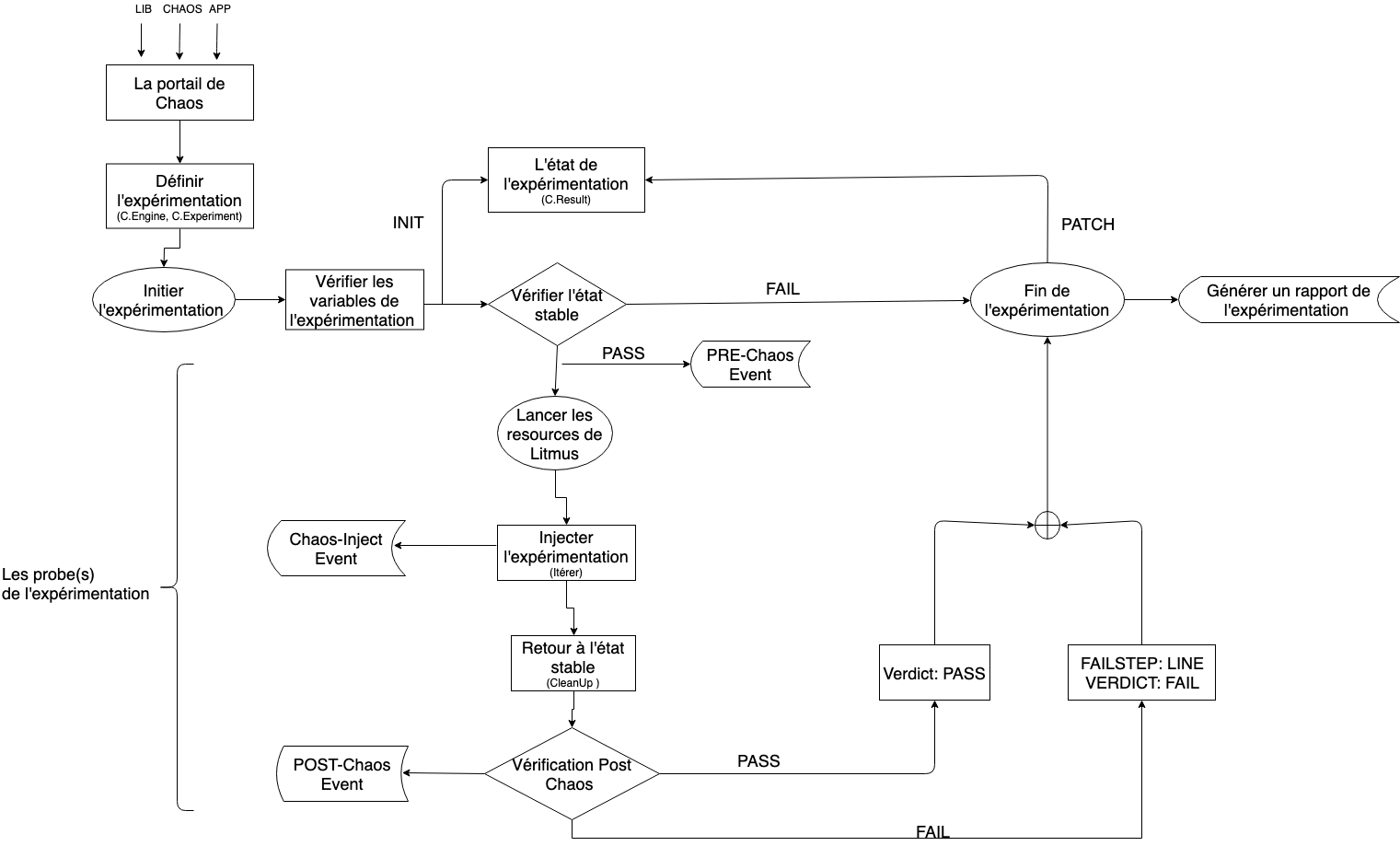
Installation de Litmus et de son frontend sur GKE
Nous allons installer Litmus sur un cluster GKE (Google Kubernetes Engine) avec Terraform, n’hésitez pas à nous suivre dans notre démonstration si vous êtes équipés des prérequis cités au début de l’article.
Pour déployer notre cluster Kubernetes nous allons utiliser le code Terraform suivant :
resource "google_container_cluster" "gke_cluster" {
project = sandbox-chaos
name = cluster-k8s
location = europe-west1-c
min_master_version = var.gke_version
network = default
remove_default_node_pool = true
initial_node_count = 1
default_max_pods_per_node = var.default_max_pods_per_node
maintenance_policy {
daily_maintenance_window {
# en heure GMT
start_time = "04:00"
}
}
}
resource "google_container_node_pool" "main-gke-simple-node-pool" {
project = sandbox-chaos
cluster = google_container_cluster.gke_cluster.0.name
name = "node-pool-chaos"
location = europe-west1-c
initial_node_count = 1
autoscaling {
min_node_count = var.node_machine_min_node_count
max_node_count = var.node_machine_max_node_count
}
node_config {
preemptible = var.node_machine_preemptible
machine_type = var.node_machine_type
oauth_scopes = local.oauth_scopes
service_account = google_service_account.gke_service_account.0.email
}
management {
auto_repair = true
auto_upgrade = true # Will follow the master version
}
upgrade_settings {
max_surge = 2
max_unavailable = 1
}
}
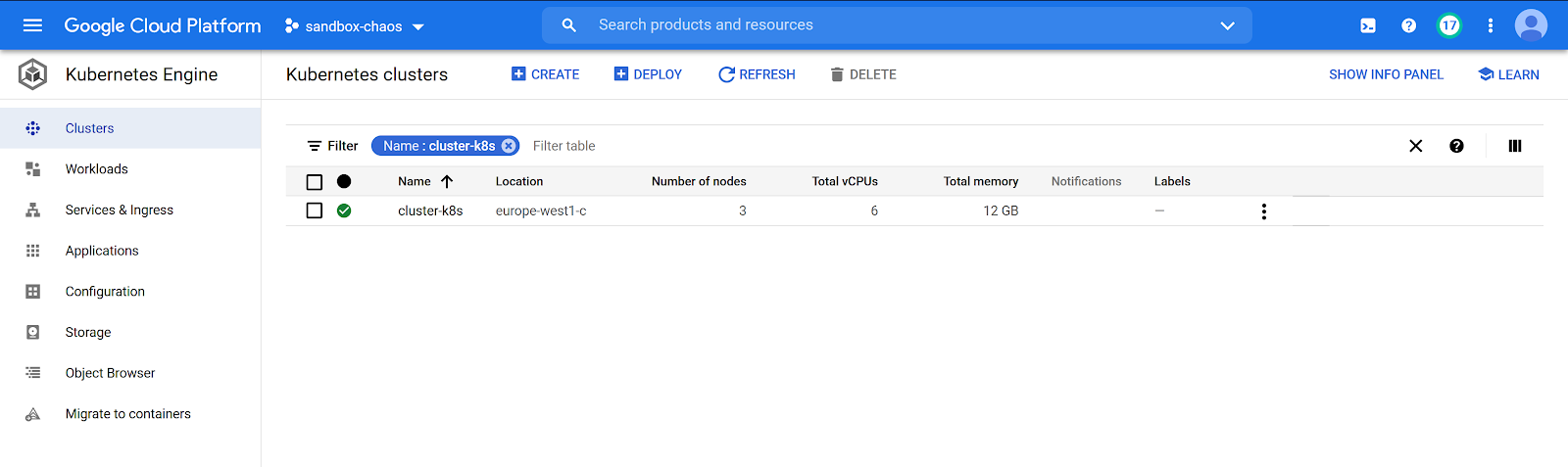
Après avoir exécuté le code Terraform, nous aurons notre cluster Kubernetes sur GCP, comme nous pouvons le constater ci-dessous :
Installation de Litmus sur le cluster Kubernetes :
Une fois notre cluster Kubernetes installé, nous pouvons passer à la phase suivante : l’installation de Litmus. Pour cela, nous vous recommandons cette documentation que nous avons utilisée si vous souhaitez plus de détails : ici
Nous allons installer Litmus avec son portail web. Cette version est encore en bêta à l’heure actuelle et devrait passer en version stable dans le courant de l’année 2021.
Avant tout, il faudra que nous nous connections au cluster Kubernetes. Connectez-vous à GCP et ouvrez votre Google Cloud Shell pour obtenir un environnement prêt à l’emploi (ou utilisez votre environnement local). Ensuite, exécutez la commande suivante, elle nous permettra de nous connecter à notre cluster K8S :
# gcloud container clusters get-credentials cluster-k8s --zone europe-west1-c --project sandbox-chaos
Maintenant que nous sommes connectés, nous allons pouvoir installer Litmus via une simple commande kubectl (de la même manière que si vous faisiez un curl avec pipe dans votre shell pour exécuter un script venant d’un repo distant, nous ne saurons que vous conseiller de relire le manifest avant pour vérifier ce que vous installez dans votre cluster) :
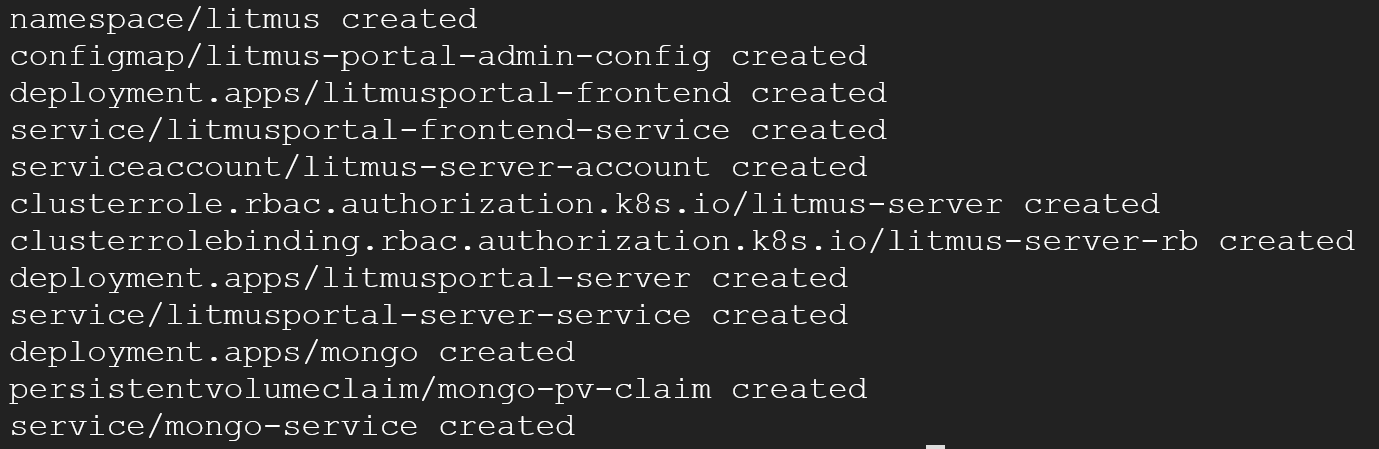
kubectl apply -f https://raw.githubusercontent.com/litmuschaos/litmus/v1.13.x/litmus-portal/cluster-k8s-manifest.yml
Au terme de l’exécution de cette commande nous devrions voir apparaître ce résultat :
Et si nous regardons dans la console GCP au niveau des workloads de Kubernetes, nous pourrons voir les microservices suivants :
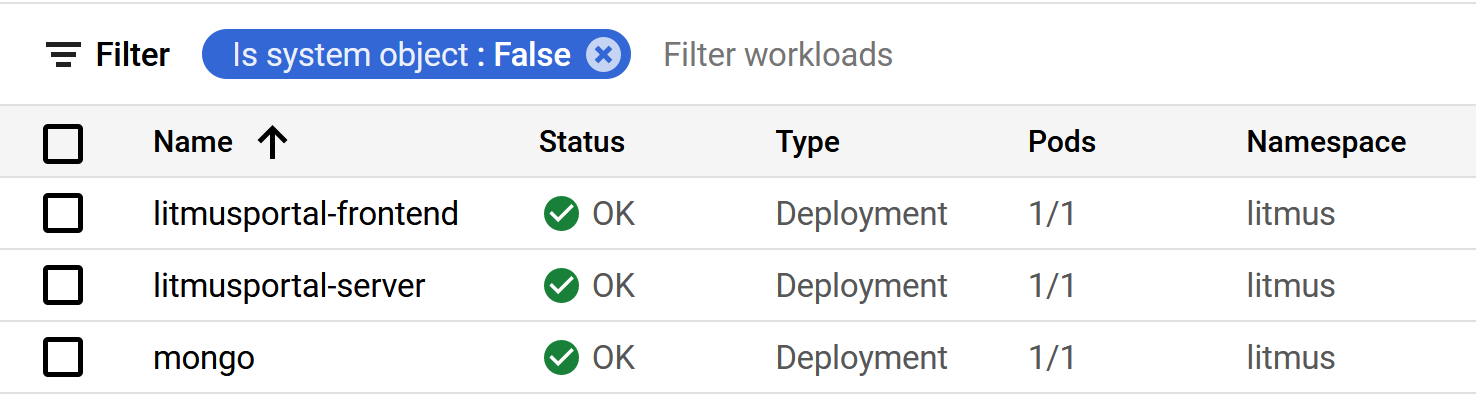
Si c’est le cas, bravo ! Nous avons installé avec succès Litmus sur un cluster Kubernetes dans GCP !
Par défaut, le Service “litmusportal-frontend-service” est configuré en Nodeport. Si vous voulez le passer en Loadbalancer, il vous suffira d’exécuter cette commande :
kubectl patch svc litmusportal-frontend-service -p '{"spec": {"type": "LoadBalancer"}}' -n litmus
Maintenant que tout est OK, nous allons pouvoir accéder à Litmus. Cliquez sur l’URL d’endpoint associée au pod “litmusportal-frontend-service”, cela nous emmènera sur le portail Litmus :
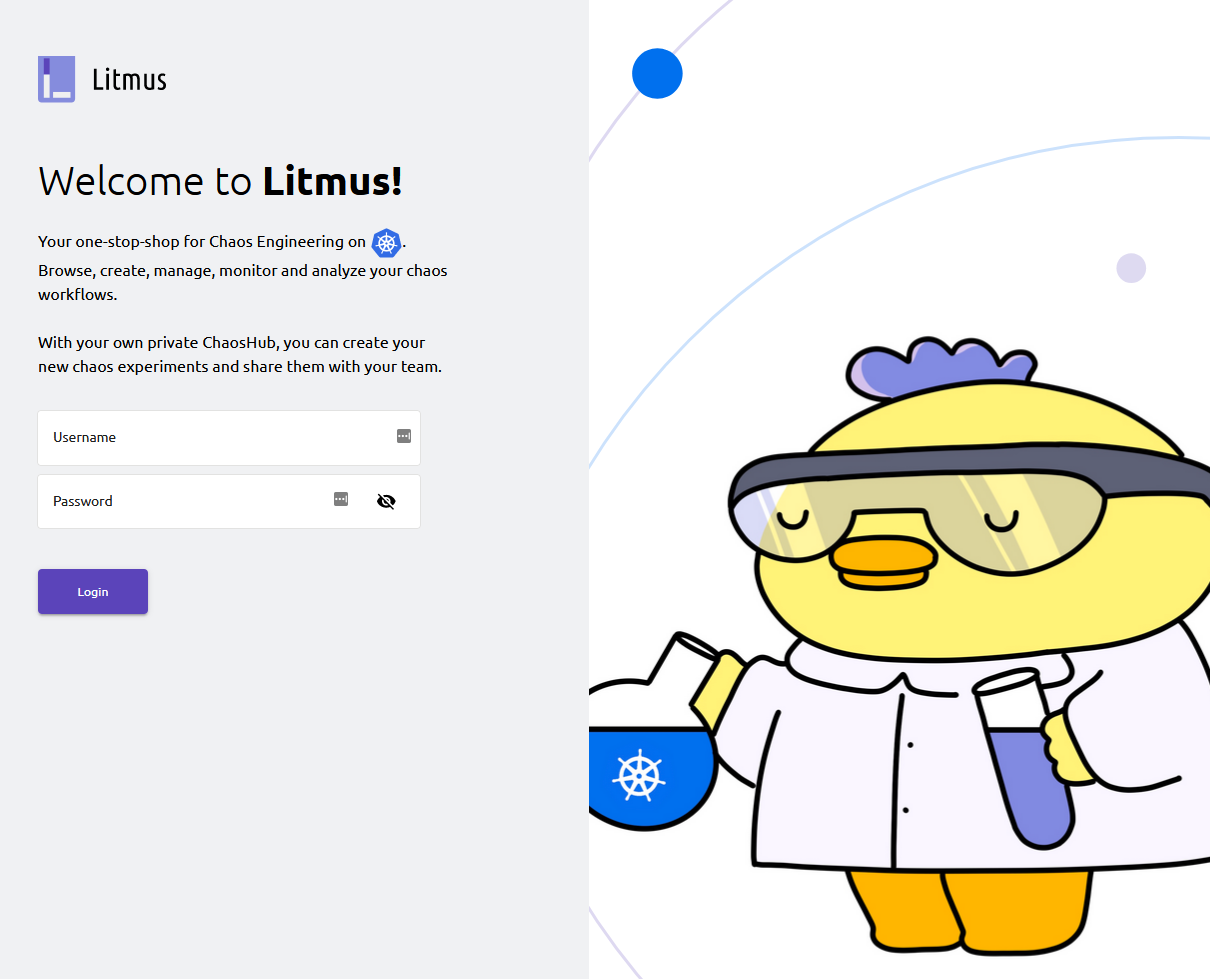
Les identifiants par défaut pour se connecter au portail Litmus sont :
- Utilisateur : admin
- Mot de passe : admin
Juste après avoir réalisé notre première connexion, Litmus nous demandera de renseigner le nom de notre projet et de modifier notre mot de passe. Après avoir fini la configuration de notre projet, nous aurons pleinement accès à notre portail Litmus.
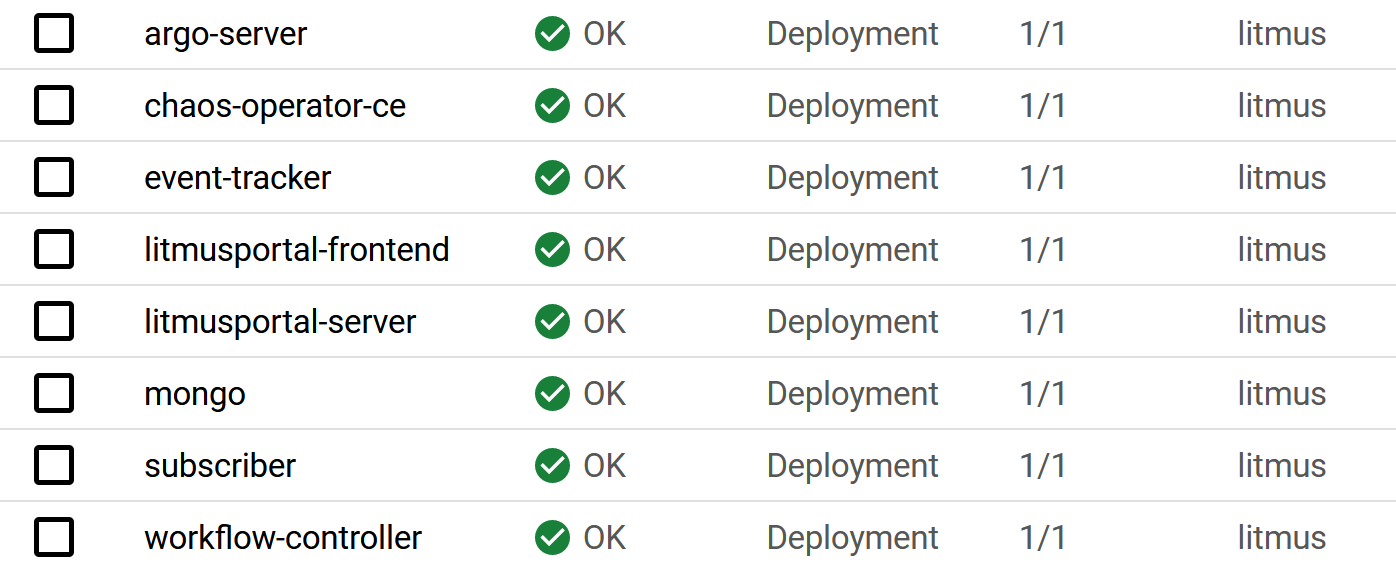
En revanche, une fois la configuration de notre projet terminée, de nouveaux éléments sont apparus ! Nous pouvons constater que de nouveaux déploiements ont été ajoutés à notre cluster. Les composants qui ont été ajoutés sont les suivants:
- argo-server : Le serveur API pour les workflows, il permet d’avoir une UI.
- chaos-operator-ce : Le contrôleur décisif de Litmus qui surveille les ressources créées par le ChaosEngine et lance le chaos-runner pour exécuter les expérimentations qui y sont définies. De plus, il gère l’interruption / le redémarrage des expérimentations et met à jour l’état des exécutions dans le ChaosEngine.
- chaos-agent-event-tracker : Il surveille les modifications apportées aux ressources de l’application sur le cluster.
- chaos-agent-subscriber : L’agent de Chaos principal de Litmus qui se trouve dans le cluster cible (Target) et interagit avec GraphQL.
- workflow-controller : Le contrôleur Argo qui exécute les étapes définies dans les spécifications de Workflow Chaos. Il met à jour le statut du workflow dans Workflow/CronWorkflow CR.
Ces composants sont les briques de l’infrastructure Litmus qui permettront au service de travailler au corps nos environnements Kubernetes au travers d’expérimentations chaos.
Zoom sur la partie chaos-portal :
Présentation de l’interface graphique
Avant de déclencher le chaos sur notre cluster, nous vous proposons de présenter très brièvement l’interface web de Litmus :
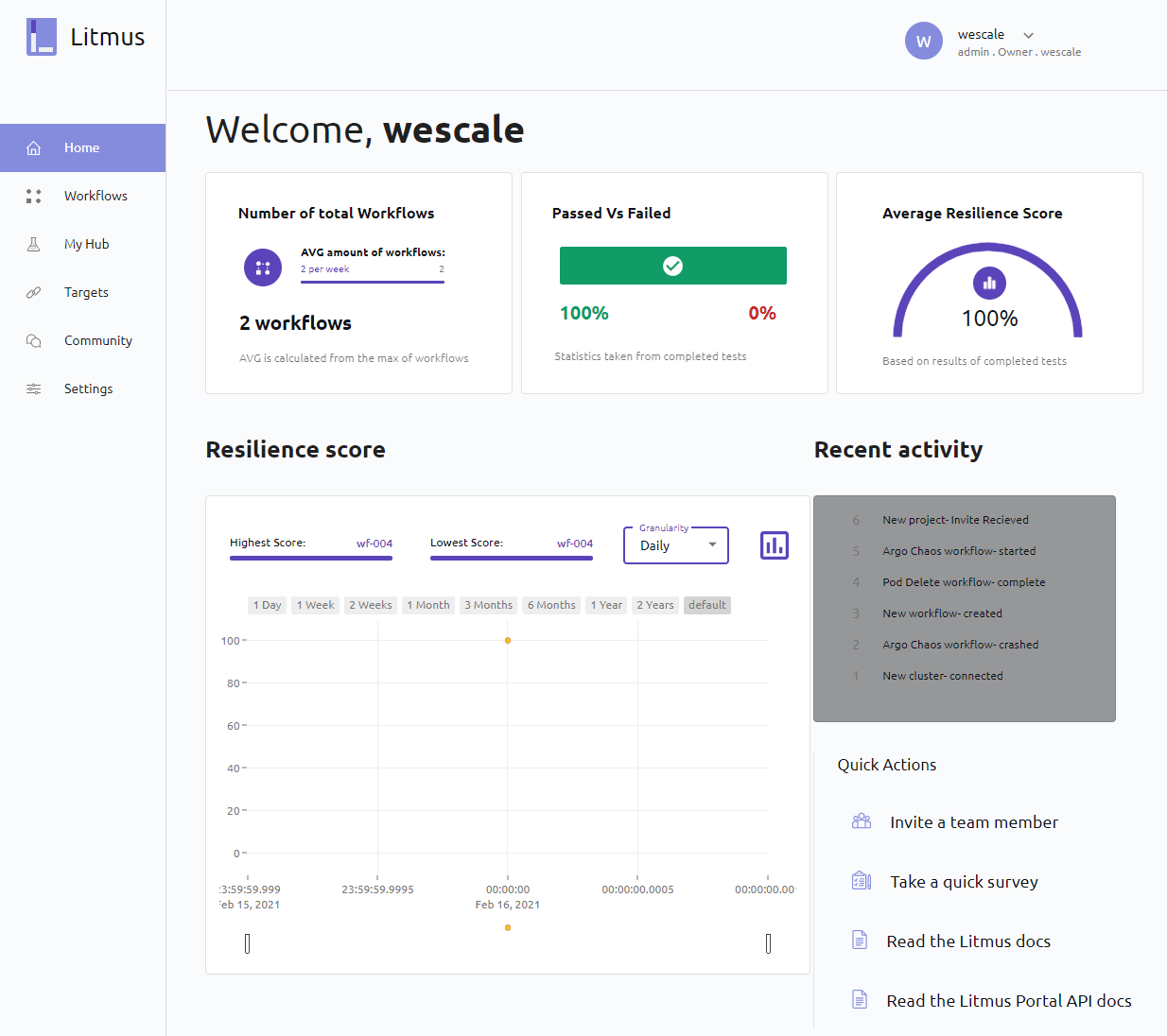
- Home : Page d'accueil, elle permet d’obtenir un récapitulatif de notre activité sur Litmus, ainsi que le résultat de nos différentes expérimentations de Chaos, ainsi que notre score de résilience (nous reviendrons sur cette notion en détail plus tard dans l’article)
- WorkFlows : Gestion, orchestration et analyse de nos workflows
- MyHub : Gestion de nos Hubs Chaos
- Targets : Gestion de nos clusters Kubernetes
- Community : Page vitrine de la communauté Litmus
- Settings : Édition du compte et, si nous avons les droits suffisants, les autres utilisateurs et groupes.
Chaos Hub
Dans la section “My Hub” du portail Litmus, nous pouvons voir un élément nommé “Chaos Hub”. Celui-ci contient 47 expérimentations que nous pouvons utiliser pour tester la résilience de notre cluster Kubernetes. Ce hub est gracieusement mis à disposition par la communauté Litmus.
Rappel : une expérimentation est un test de Chaos spécifique.

Nous avons des expérimentations en tout genre que ce soit pour la partie master de Kubernetes, pour les nœuds, pour les pods, pour la partie réseau et même pour la partie Cassandra et OpenEBS.
Il est aussi possible dans la partie “My Hub” de rajouter d’autres hub. Ainsi, vous pouvez créer votre propre collection de tests de Chaos et les partager au sein de votre organisation ou à toute la communauté !
Jouer avec Litmus
Pour découvrir les interactions basiques avec Litmus nous allons dans premier temps mettre en place un environnement de test. Puis dans un second temps, nous travaillerons sur notre environnement de test au travers d’un workflow que nous mettrons en place. Et enfin dans un troisième et dernier temps, nous analyserons le résultat de celui-ci.
Installer le “magasin de chaussettes” sur GCP
La communauté Litmus met à disposition un environnement de démonstration pour pouvoir tester les capacités de sa solution. Nous allons l’installer et l’exploiter. Dans quelques instants, nous serons les heureux propriétaires d’un magasin de chaussettes !
- Connectez-vous à votre compte GCP et accéder à votre Cloud Shell
- Connectez-vous au cluster :
gcloud container clusters get-credentials cluster-k8s --zone europe-west1-c --project sandbox-chaos
- Téléchargez le repo de démo et allez dans le répertoire :
# git clone https://github.com/litmuschaos/litmus-demo.git
# cd litmus-demo
- Utilisez le script pour installer le sock-shop sur GKE :
./manage.py start --platform GKE
NB: Il est possible qu’un message d’erreur apparaisse concernant le module reportlab, pour corriger cela, téléchargez les dépendances via :
pip3 install -r requirements.txt
Choisissez ou non la collecte de données :
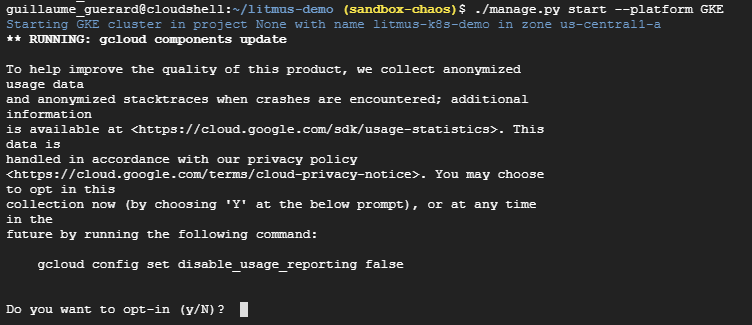
- Une fois l’opération terminée vous devriez obtenir ce message :
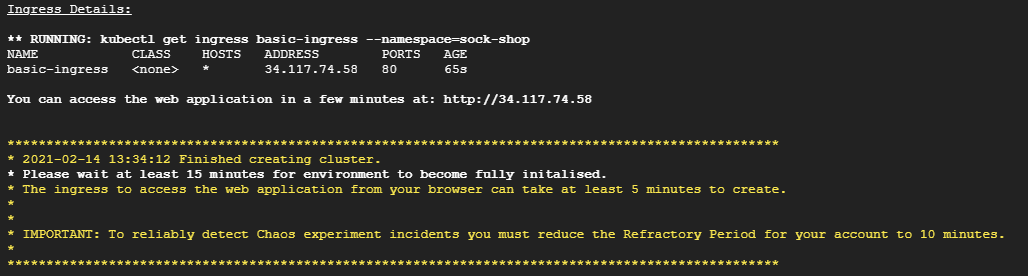
- Allez sur l’adresse web qui vous est affichée dans votre terminal (dans notre exemple : http://37.117.74.58), vous devriez arriver sur votre site :
- Vous devriez voir de nouveaux déploiements via votre interface GCP :
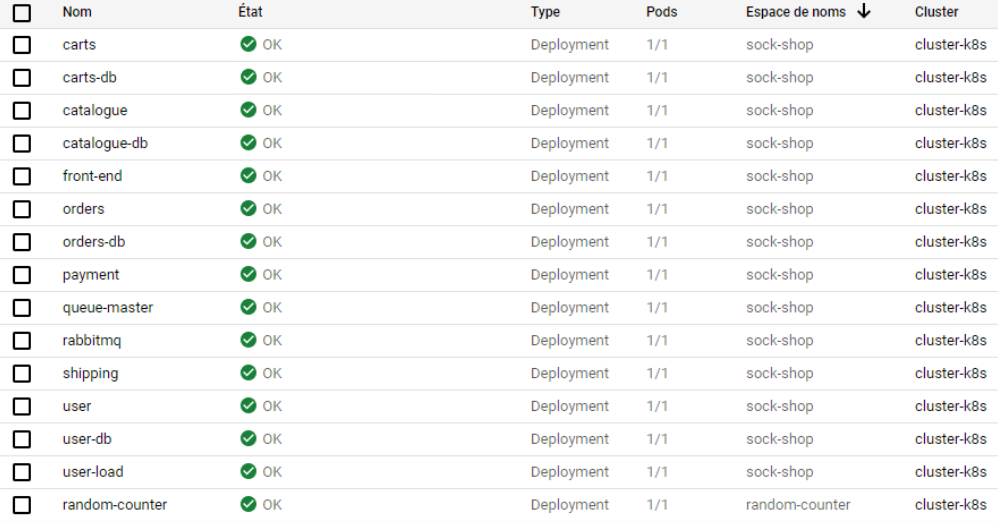
Pour arrêter la plateforme de test vous pouvez utiliser la commande :
./manage.py --platform GKE stop --project {GC_PROJECT}
Si les indications ci-dessus ne sont pas suffisantes pour mettre en place l’environnement de test, n’hésitez pas à regarder le GitHub associé pour y retrouver des éléments d’investigation : https://github.com/litmuschaos/litmus-demo.
Ajouter un cluster distant sur Litmus
Par défaut, dans la partie Targets de Litmus portal, nous avons qu’une seule target qui est le cluster “self-cluster”, c’est-à-dire notre cluster lui-même. Chaque cluster que vous souhaitez exploiter dans une expérimentation Chaos doit être ajouté en tant que target.
Cette liaison entre Litmus et un cluster est opérée par la brique “Subscriber”.
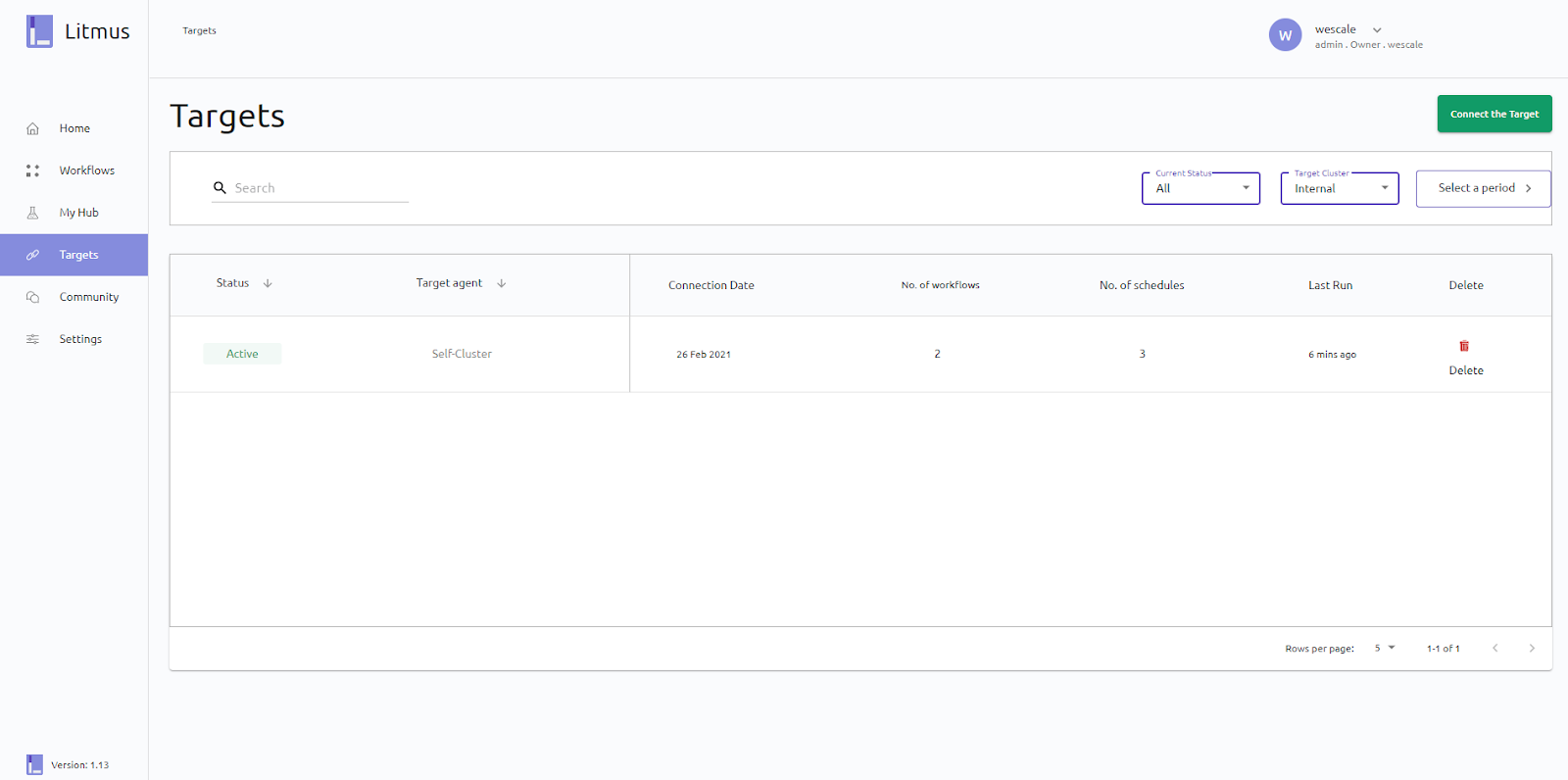
Nous avons donc la possibilité de lier d’autres clusters Kubernetes à Litmus. Peu importe leur localisation, qu’ils soient chez d’autres cloud providers tels que AWS, Azure, Scaleway, on-premise ou autre, à condition que la configuration réseau le permette bien entendu.
Nous allons connecter un autre cluster Kubernetes, un différent de celui où se trouve notre infrastructure Litmus, un cluster GCP dans une autre zone mais dans le même projet. Pour le créer nous utilisons le même code Terraform que pour créer notre cluster actuel. Créez-le et tentez de vous y connecter.
gcloud container clusters get-credentials cluster-2 --zone us-central1-c --project sandbox-chaos
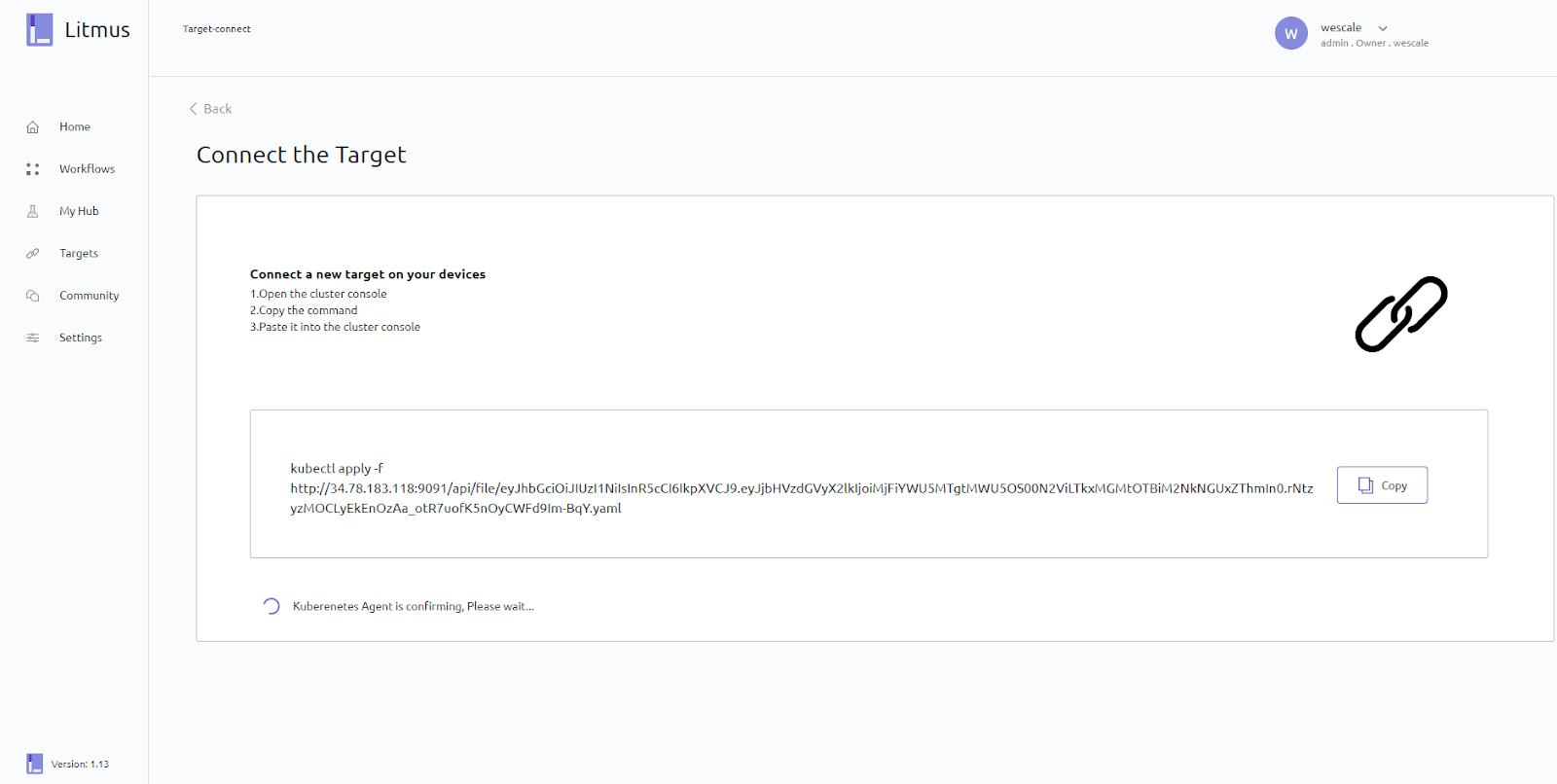
Pour en ajouter un, il faut ouvrir l’onglet Targets et cliquer sur Connect the Target, ce qui nous amènera sur cette page :
Pour avoir plus de détails sur les targets et les deux modes de connexion, nous vous invitons à explorer ce document fait par la communauté:
UserGuide for Litmus Portal
Litmus-Portal User Guide Litmus Release: 1.11.0 Portal Release: Beta0 Introduction - Litmus Portal 4 Installation 4 Prerequisite 4 Installation 4 How to access the Portal 4 Litmus Portal 6 Portal Admin 6 Portal User 6 Portal Access 6 First login 6 Home Page 9 Settings 10 My ...

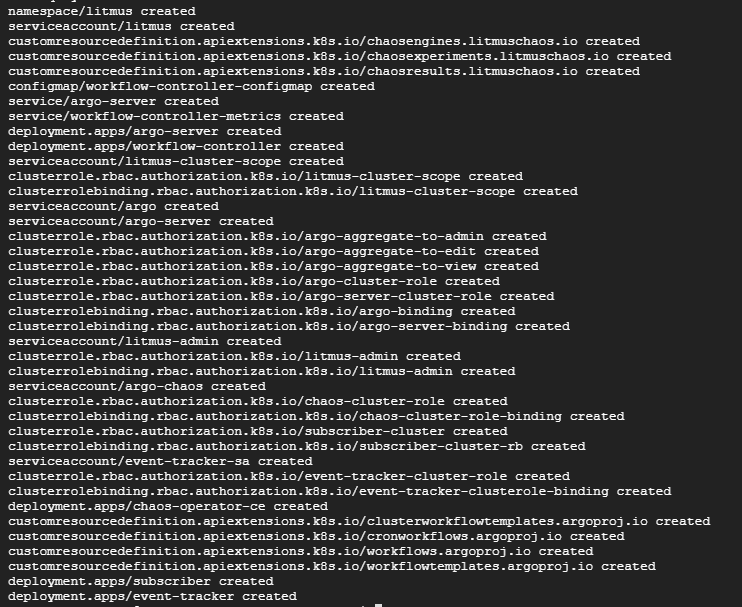
En suivant les instructions données dans l’interface, nous allons connecter Litmus à notre nouveau cluster. Cette commande va mettre en place les ressources nécessaires pour que Litmus puisse interagir avec notre cluster pour réaliser nos différents scénarios de Chaos. La commande devrait avoir ce format :
kubectl apply -f http://<ip>:9091/api/file/<random_string>.yaml
Vous devriez obtenir un résultat équivalent :
Et votre nouvelle Target devrait obtenir un statut actif :

Nous pouvons voir que nous avons bien le cluster “self-cluster” et l’autre cluster que nous venons d’ajouter qui sont rattachés à Litmus.
Créer un workflow via le chaos-portal
Workflow de destruction de pod
Pour tester Litmus, nous allons travailler sur le “sock-shop” avec un scénario très simple : la destruction d’un pod. Nous vérifierons le comportement de notre pod et les déductions de Litmus.
Par défaut lorsque nous installons Litmus, celui-ci crée des Role Based Access Control (RBAC) au sein du cluster Kubernetes et les mappe en ClusteRoleBinding pour que les RBAC soient appliqués sur tout le cluster et non sur un espace de nom spécifique. En revanche, il n’installera un service account en mode admin par défaut, que dans le namespace où nous avons installé Litmus.
apiVersion: v1
kind: ServiceAccount
metadata:
name: litmus-admin
namespace: litmus
labels:
name: litmus-admin
Pour l’appliquer directement utilisez la commande :
kubectl apply -f https://litmuschaos.github.io/litmus/litmus-admin-rbac.yaml
Si vous souhaitez l’exécuter sur un autre namespace il vous faudra obligatoirement rajouter le service account sur l’espace de nom que vous souhaitez utiliser pour réaliser vos expérimentations de Chaos.
Commençons par créer notre workflow :
1 - Connectez-vous à Litmus via l’interface web
2 - Allez dans l’onglet Workflows
3 - Cliquez sur Schedule a Workflow
4 - Configurez :
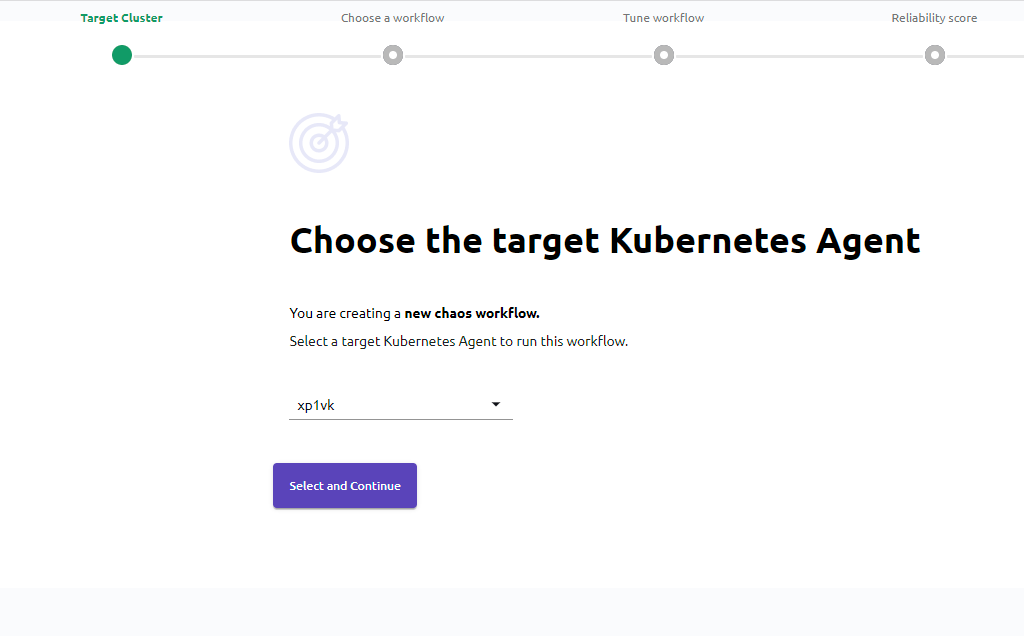
Target Cluster
Dans cette section, nous allons choisir l’agent cible (que nous avons installé au préalable sur un cluster Kubernetes). Concrètement, cette étape nous permet de sélectionner sur quel cluster le workflow portera.
- Sélectionnons Self-cluster, car dans notre cas le cluster que nous utilisons est le même que sur lequel nous avons installé le sock-shop.
- Cliquons sur Select & Continue

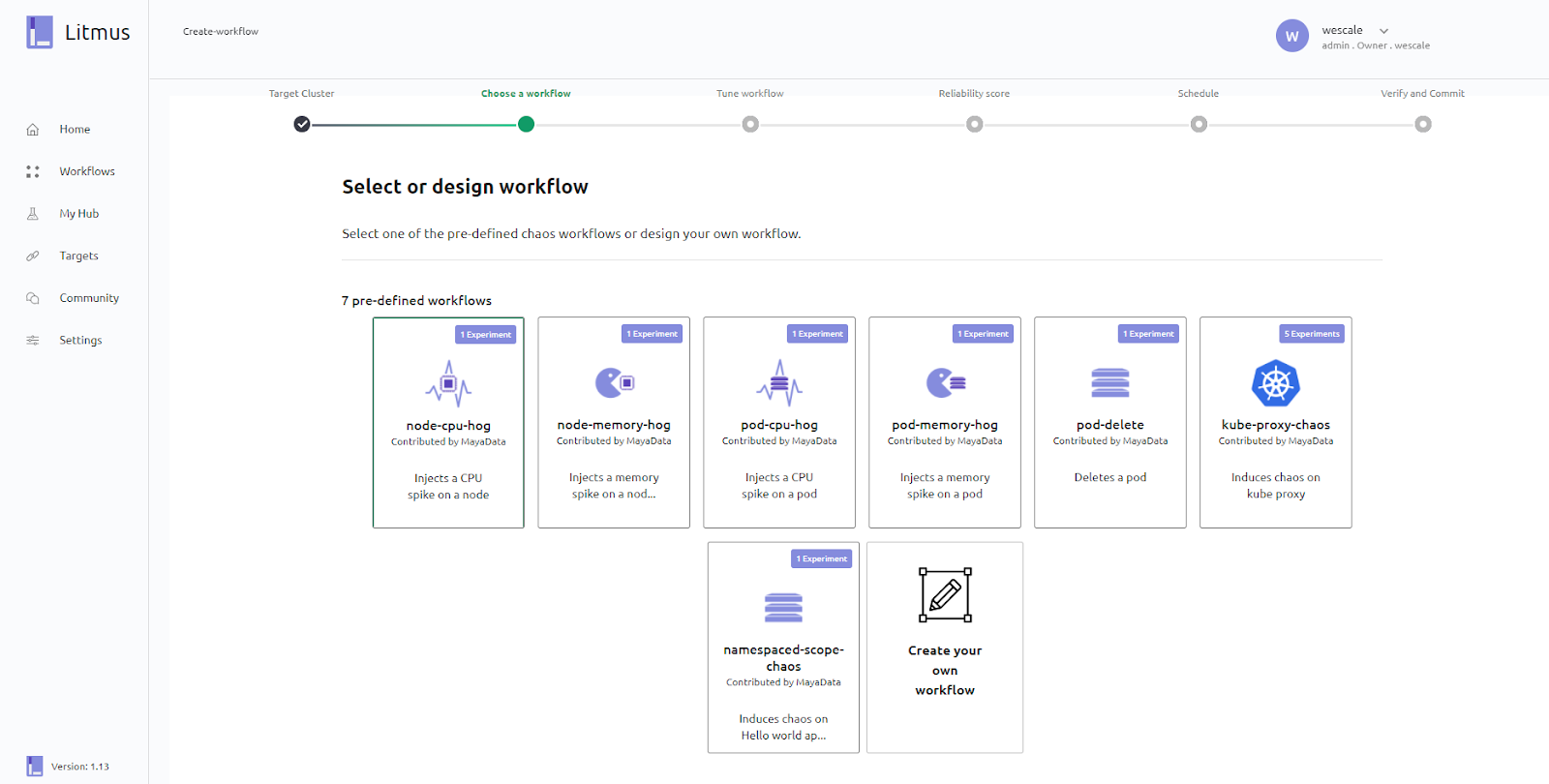
Choose workflow
Dans cette section, vous devez définir le workflow à réaliser, c’est-à-dire l’ensemble de tests que vous souhaitez exécuter. Des workflows prédéfinis vous sont proposés par défaut, mais vous pouvez bien entendu créer les vôtres et c’est ce que nous allons faire :
- Cliquez sur Create your own workflow
- Une nouvelle page devrait s’ouvrir. Au travers de celle-ci, vous allez pouvoir nommer et décrire vos workflows mais surtout y inscrire la première expérimentation de celui-ci (vous pourrez en ajouter d’autres juste après). Renseignez, ou laissez les valeurs par défaut :
- Workflow Name: wf-test-pod-delete
- Choose the Hub (Sélectionnez le Hub où se situe votre expérimentation, ChaosHub est celui de Litmus) : ChaosHub
- Choose the experiment (l’expérimentation que vous souhaitez exécuter dans notre workflow) : generic/pod-delete
- Choose NameSpace (l’espace de nom associé à l’expérience) : litmus
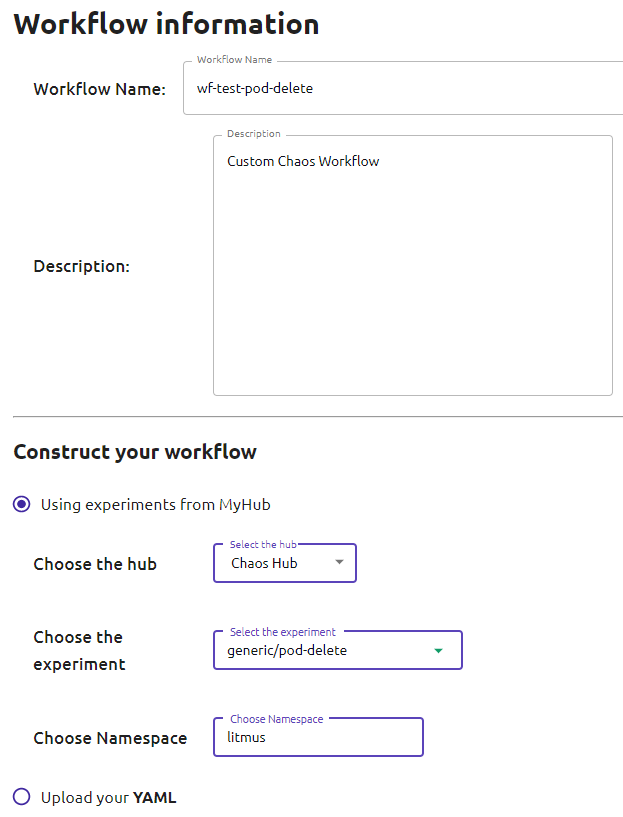
NB : Il est important de préciser que vous auriez aussi pu renseigner directement une expérimentation au format YAML.
- Cliquez sur Next
- Nous avons ajouté une expérimentation pour spécifier son fonctionnement et son périmètre. Litmus nous demande des informations additionnelles. Renseignez :
- appns (namespaces associé à notre environnement cible) : sock-shop
- applabel (label associé à nos pods cibles) : app=sock-shop,name=front-end
- appkind (objet ciblé par l’experiment) : deployment
- annotationCheck : false
Le paramètre annotationCheck n’est pas à prendre à la légère. C’est le garde-fou Litmus! Spécifiez le à “true” dans un cluster entreprise. Il permet de spécifier que Litmus ne peut interagir avec un objet tant qu’il ne possède pas l’annotation litmuschaos.io/chaos="true".
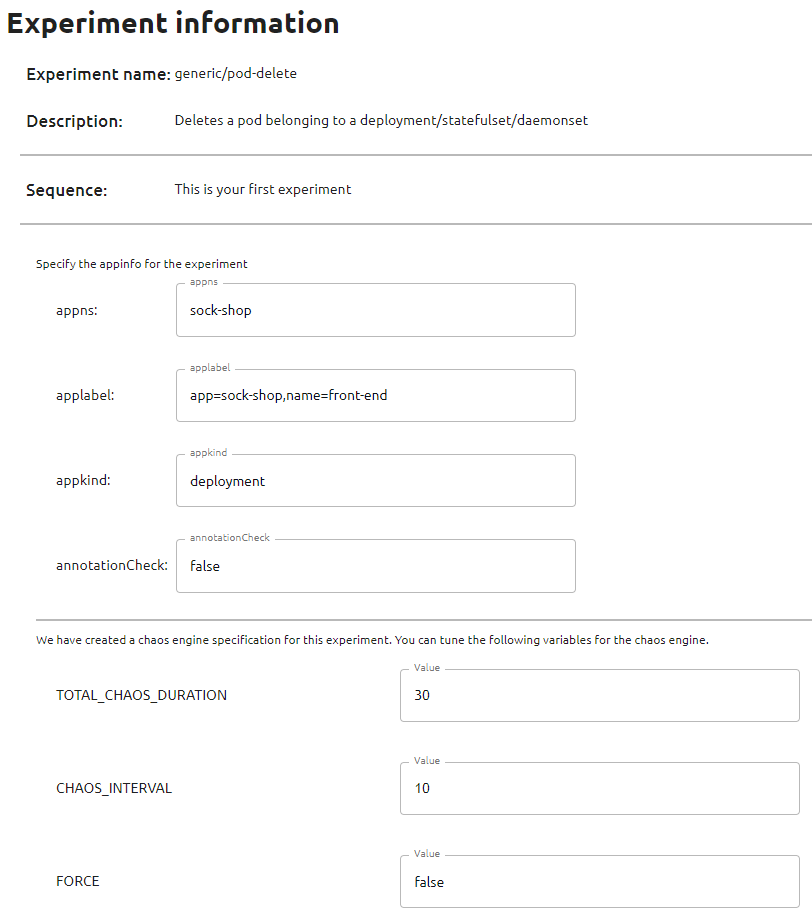
- Cliquez sur Add experiment
- Cliquez sur Finish adding experiments
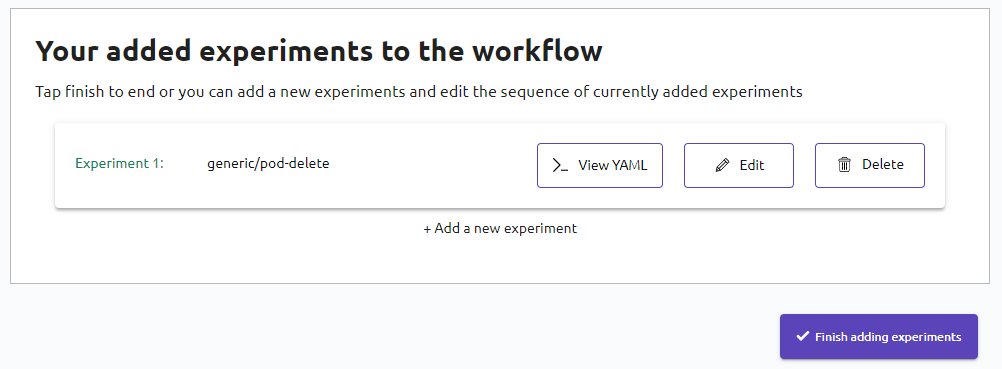
Tune workflow
Dans cette section vous pouvez éditer votre workflow, l’adapter à votre besoin, le copier ou bien encore le télécharger.
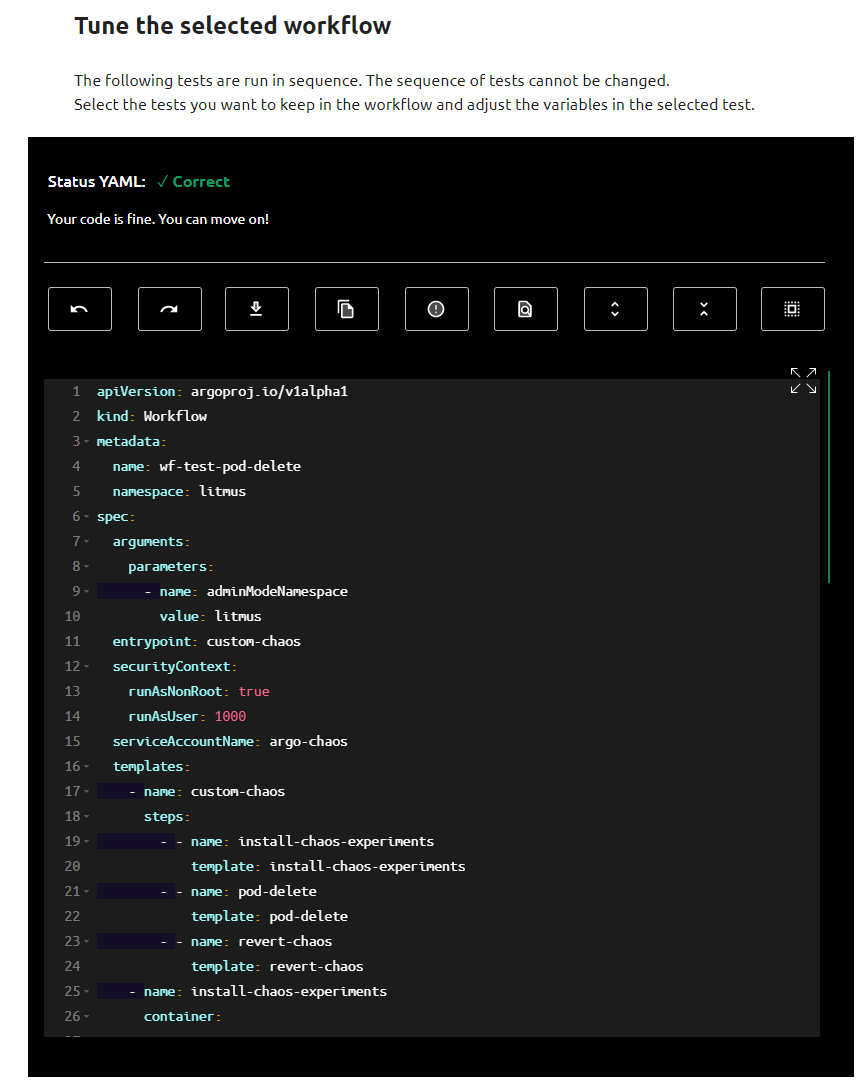
- Cliquez sur Next
Reliability score
Au cours de cette section, nous pourrons attribuer un score de fiabilité à chaque expérimentation que nous allons réaliser. Chaque expérimentation n’a pas autant de valeur qu’une autre au sein d’un workflow. Cette note que nous allons définir pour chaque experiment va nous permettre de définir son “poids” dans le workflow auquel elle appartient. Ce qui permettra à Litmus d’attribuer une note plus juste au résultat du workflow. En fonction de la réussite ou l’échec de chacune de nos expérimentations, notre workflow se verra attribuer un score de fiabilité adapté à l’importance de chacune des expérimentations. Par exemple, si nous créons dans un même workflow 3 experiments, dont 2 avec un poids de 5, et un autre avec un poids de 10. Si l’experiment de poids 10 échoue, mais que ceux à 5 réussissent, alors nous aurons un score de fiabilité de 50%.
- Laissez le à 10
- Cliquez sur Next
Schedule
Dans cette section vous serez amenés à choisir à quelle occurrence vous souhaitez exécuter votre workflow. Litmus vous offre 2 possibilités :
- Schedule now : un one-shot, vous exécuterez le workflow une seule fois
- Recurring Schedule : vous avez le choix entre plusieurs occurrences (chaque heure, chaque jour, chaque semaine, chaque mois). Au travers d’un fichier YAML nous avons autant de flexibilité qu’avec une crontab, l’interface web n’offre pas encore la multitude de possibilités imaginables.
- Sélectionnez Schedule now
- Cliquez sur Next
Verify and Commit
Cette section vous permet de faire une passe finale sur la configuration de votre workflow avant de le valider.
- Cliquez sur Finish
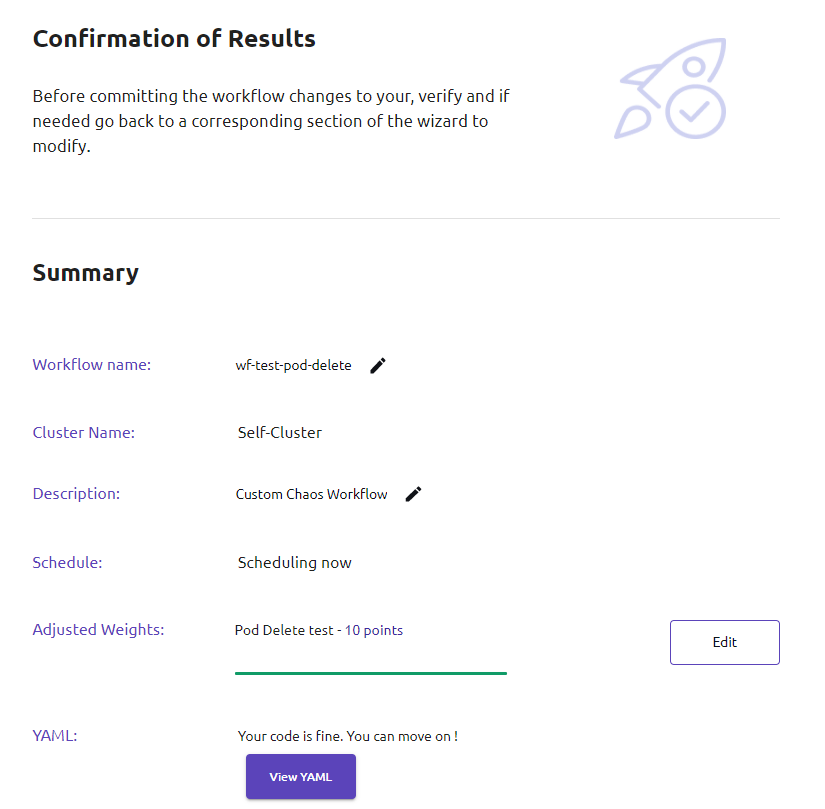
Exécution
Directement après sa création, nous pouvons voir notre workflow en cours d’exécution. Cela est notamment dû à notre paramétrage “Schedule now” qui, comme son nom l’indique, va démarrer dès maintenant, soit à sa création.

Si vous cliquez sur les trois points comme indiqué ci-dessous:

puis sur Show the workflow vous pourrez suivre l’avancement du workflow.
Une fois terminé, vous devriez obtenir un statut “Succeeded” :

Analyse
Litmus vous offre deux interfaces d’analyse de votre workflow, une détaillée et une temporelle.
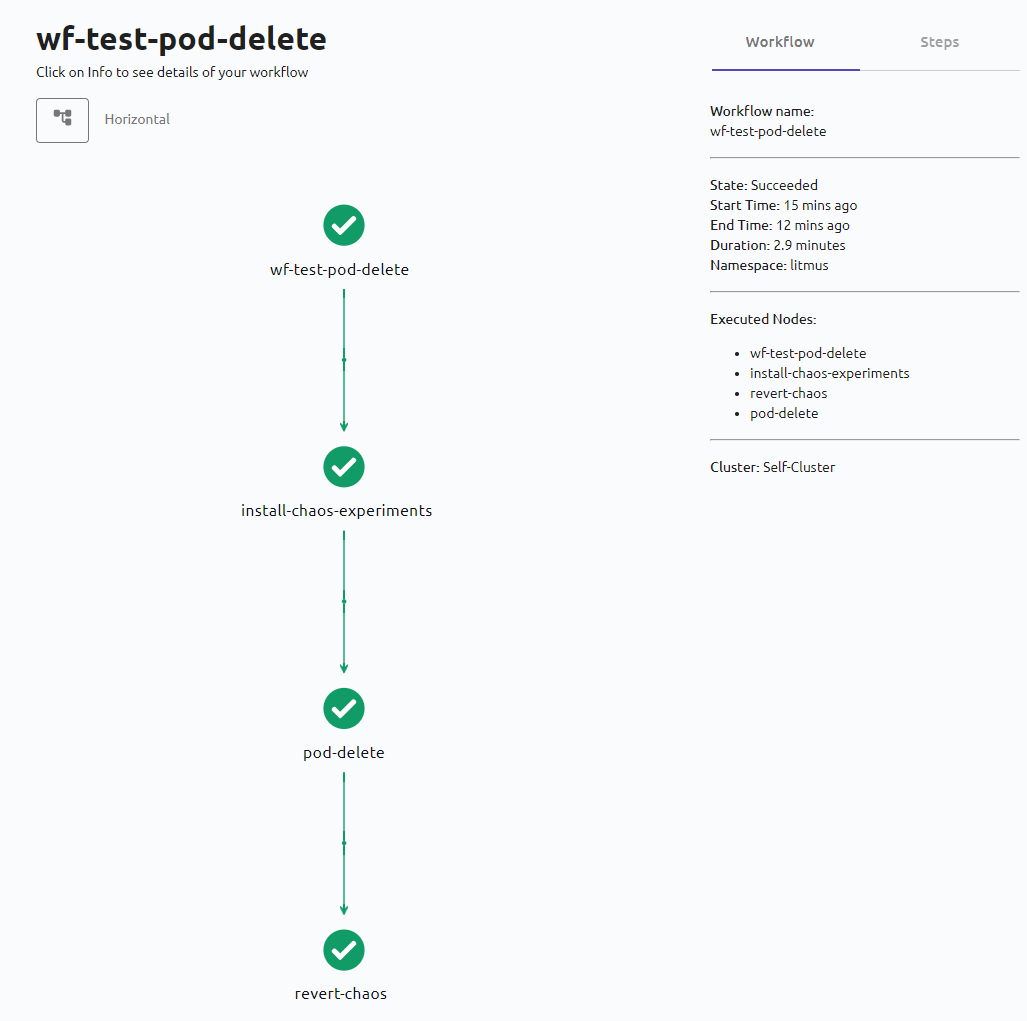
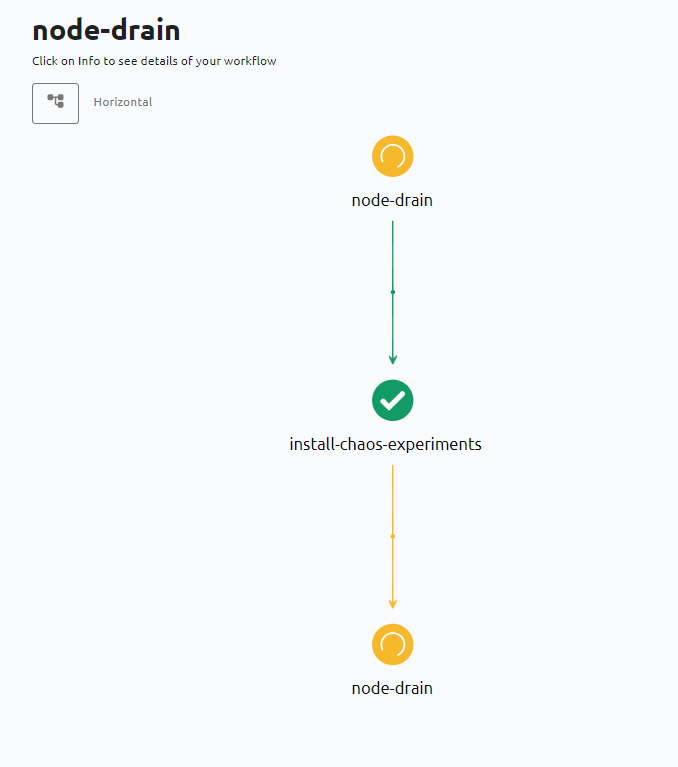
L’interface d’analyse détaillée à laquelle nous pouvons accéder en cliquant sur Show the workflow via les trois points comme indiqué ci-dessous:

nous permet de visualiser le workflow, ses différents experiments/étapes, leurs durées, leurs logs et leur statuts.
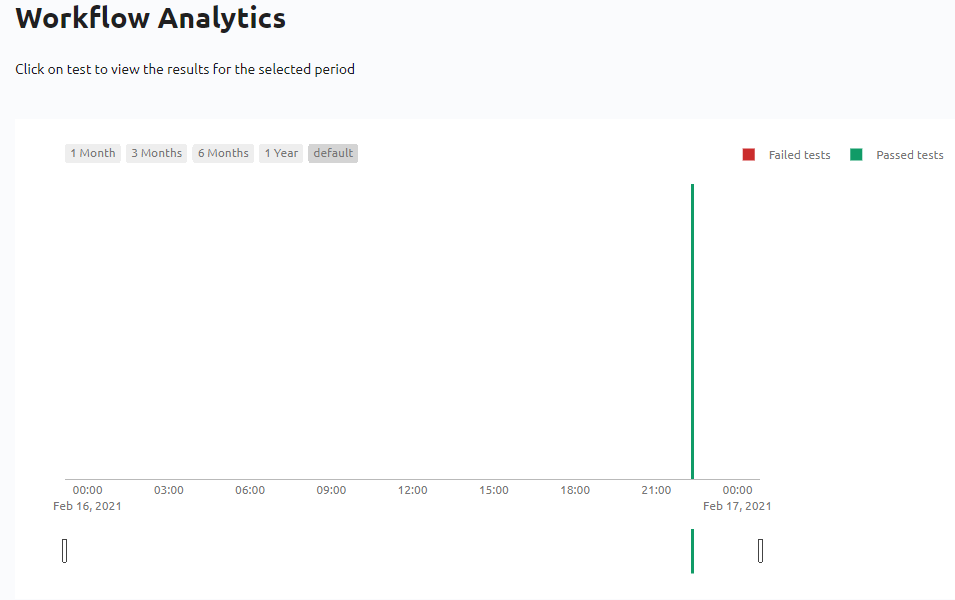
L’interface temporelle à laquelle nous pouvons accéder en cliquant sur Show the analytics.
nous permet d’obtenir un historique des réussites et des échecs du workflow :
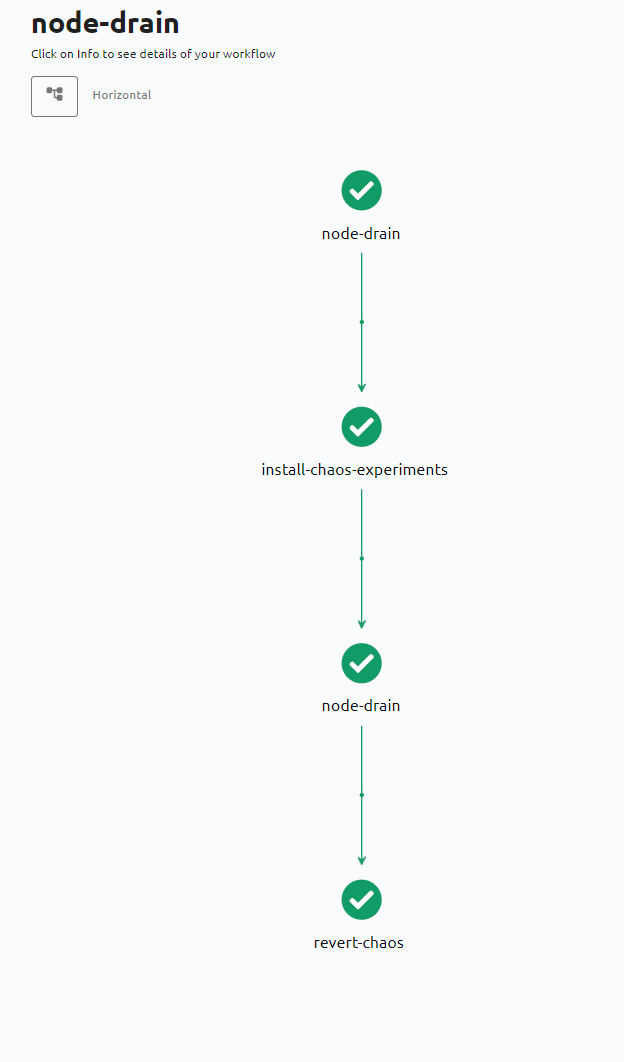
Workflow de node drain
Continuons nos expérimentations de Chaos avec cette fois-ci le node drain (vidage du nœud de tout workload) sur un nœud du cluster distant que nous avons ajouté précédemment.
Pour ce workflow, comme vous commencez à maîtriser Litmus, nous préciserons moins les détails :)
Retournez dans le processus de création d’un workflow. Lors de la sélection de l’agent, sélectionnez notre nouveau cluster :
Nous allons continuer sur “create your own workflow”, comme ce que nous avons fait avec le workflow pod-delete :
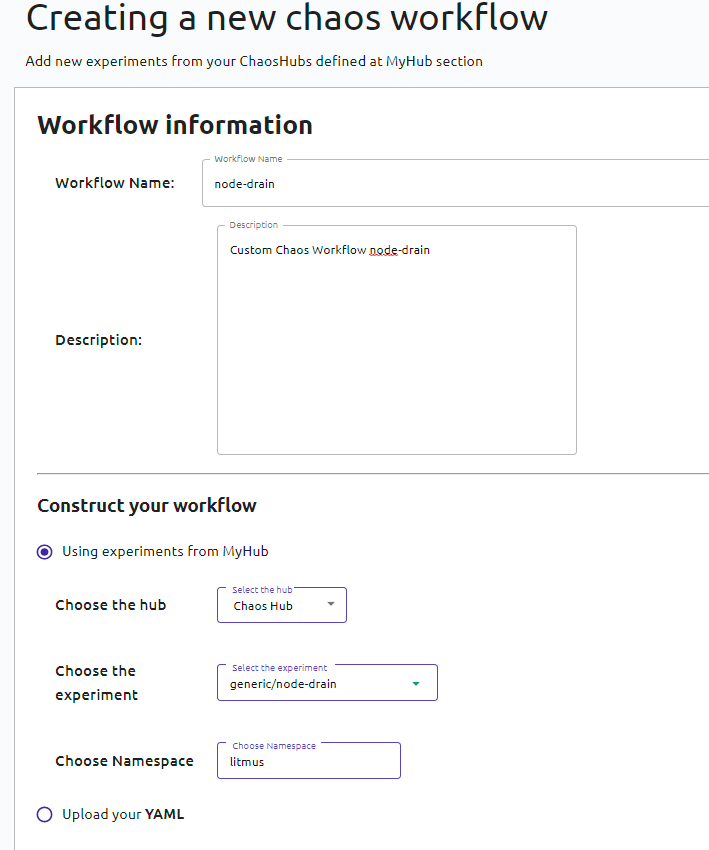
Cette fois-ci, nous utiliserons l’experiment node-drain venant du hub “Chaos Hub” :
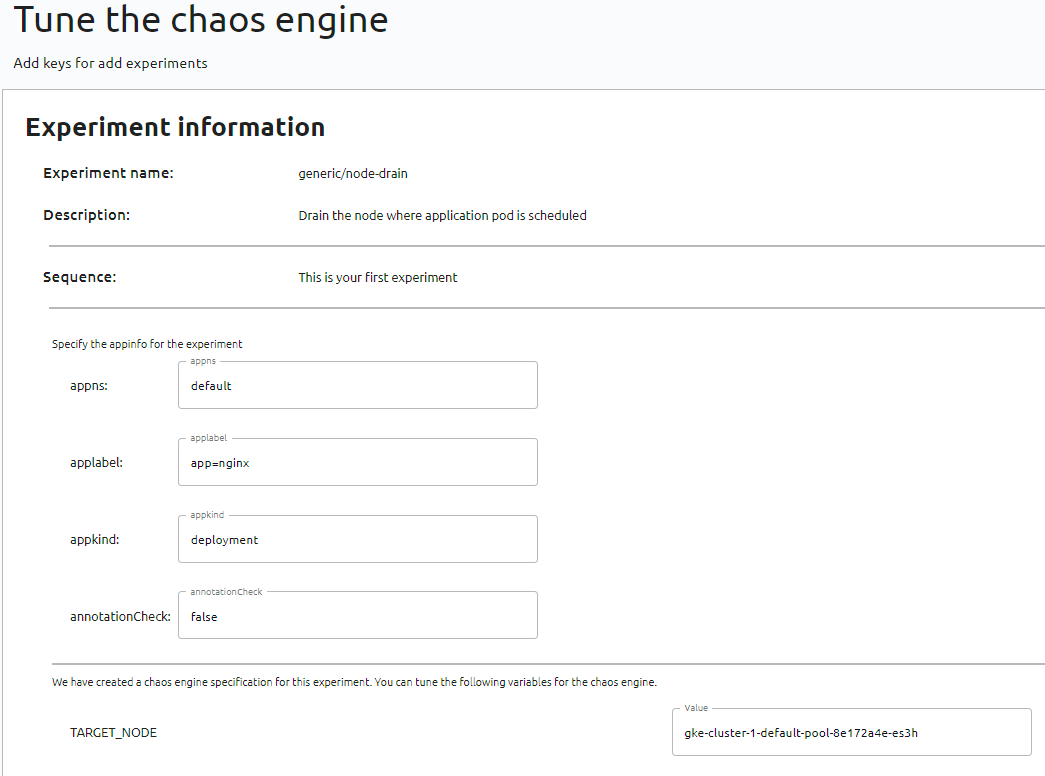
Nous devons spécifier le “Target node” afin de définir sur quel nœud le drain doit se faire.
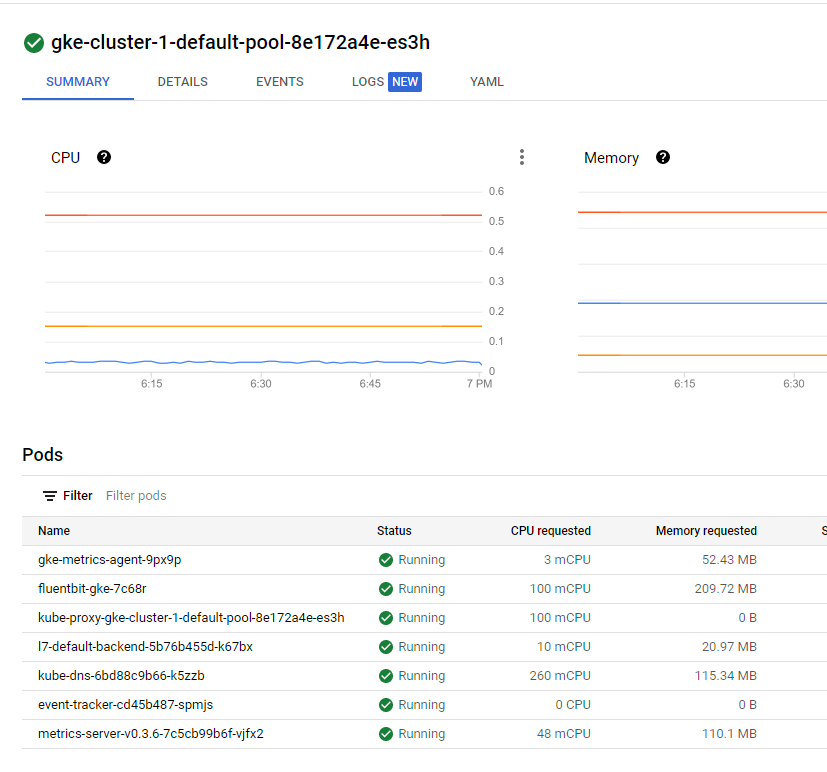
Si nous allons voir sur GCP nous pouvons observer que ce noeud a des workloads actifs :
Avant de finaliser la configuration du workflow, il faut supprimer cette partie pour que cela fonctionne, car nous définissons déjà plus bas le nœud via le “target_node”. Si on laisse ce bout de code, il ne va pas réussir à exécuter l’expérimentation node drain :
nodeSelector:
kubernetes.io/hostname: node02
Une fois le workflow créé, nous pouvons constater les résultats de son exécution. Si nous regardons côté GCP, nous verrons qu’il a créé un pod sous le nom de notre workflow.
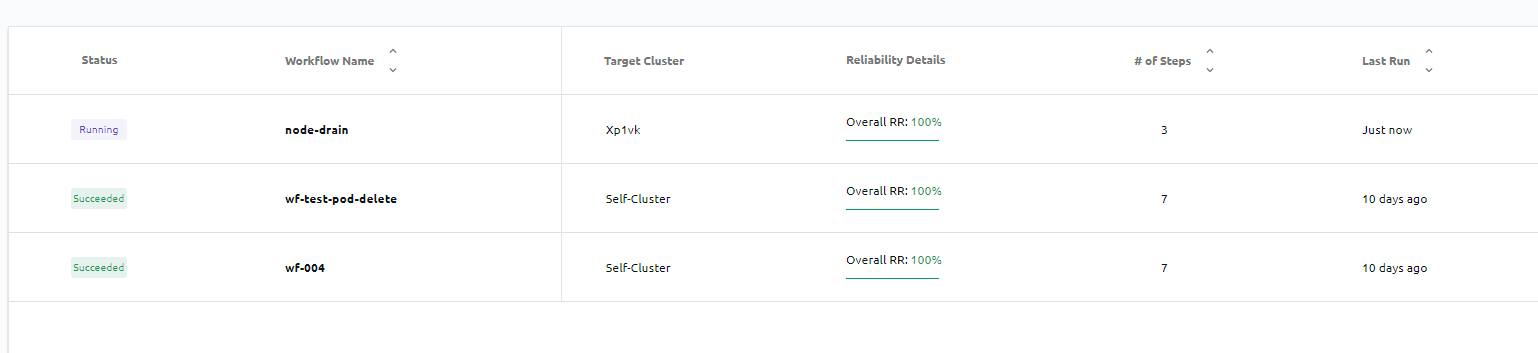
Pendant que le workflow s'exécute nous pouvons voir qu’il a bien mis en mode drain notre cluster et qu’il n’accepte plus aucun pod.
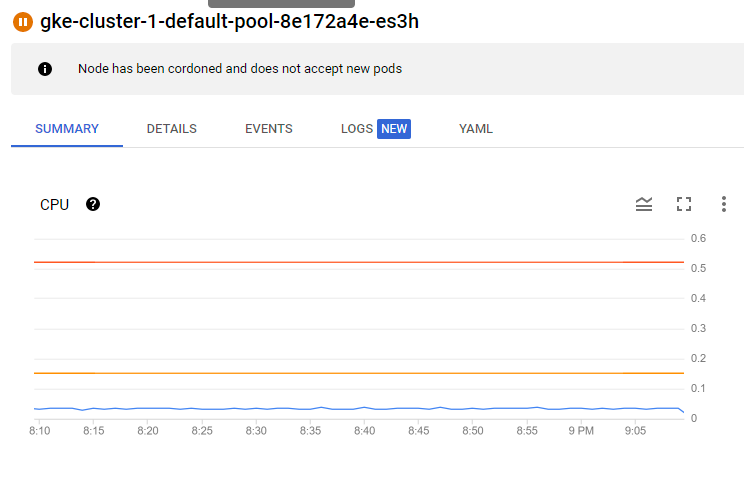
Maintenant que le workflow est complet, il a enlevé le mode drain de notre cluster, comme si rien ne s'était passé.
Pour mieux comprendre comment Litmus fonctionne, nous allons faire un focus sur ce qu’il s’est passé en arrière-plan de l’exécution de notre workflow.
Tous les workflows que nous exécutons via Litmus sont exécutés au travers d’Argo CD. Argo CD est le moteur d’orchestration d’expérimentations de Chaos de Litmus.
Vous pouvez accéder à son interface via l’endpoint fourni dans l’interface GCP au niveau du déploiement “argo-server”.
Nous pouvons voir tous les workflows qui ont été exécutés et nous retrouvons les mêmes informations que Litmus affiche dans les analyses de résultats : les graphes, les logs de chaque étape du workflow ou même le code yaml du workflow. C’est d’ailleurs dans Argo CD que Litmus vient récupérer les informations.
Nous pouvons accéder à notre workflow pod-delete exécuté précédemment :
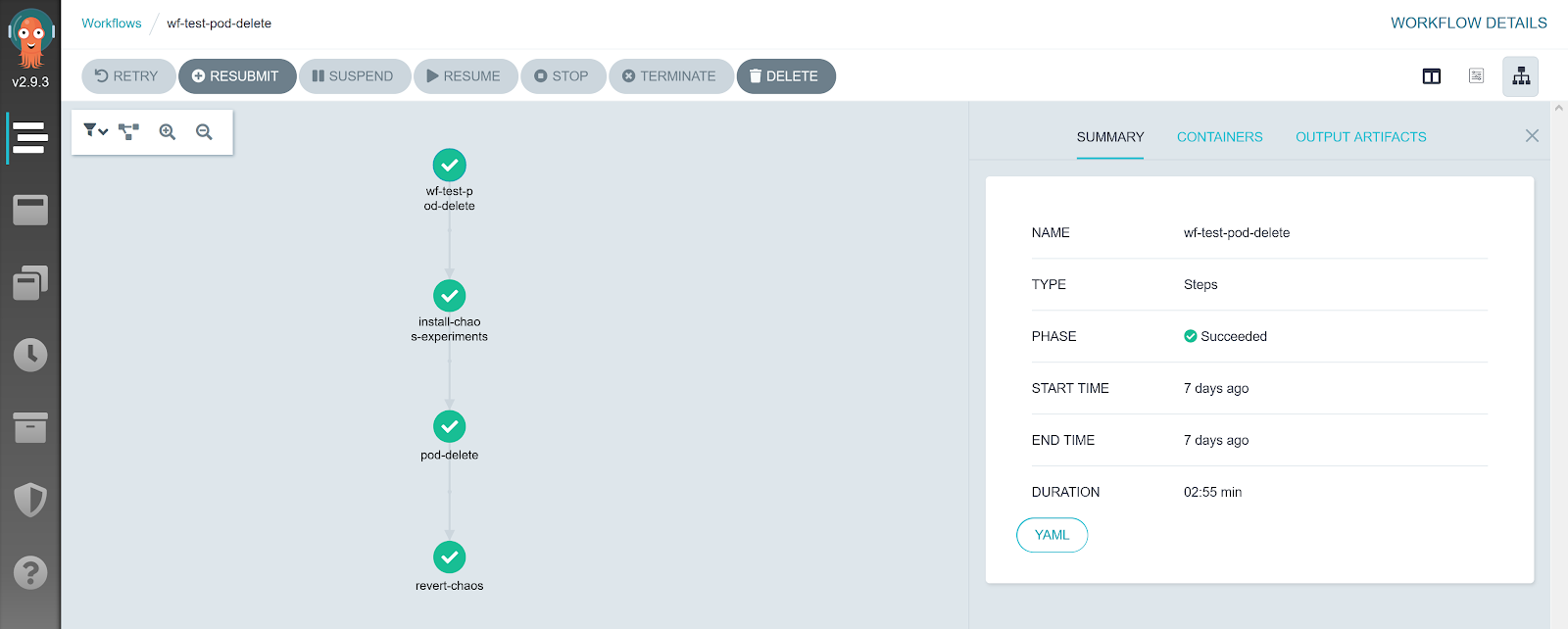
Nous pouvons cliquer sur chacune des étapes du workflow pour voir le yaml de l’exécution ou les logs.
On peut aussi directement injecter un workflow via Argo CD. En revanche, pour l’utiliser nous devons installer sa CLI sur notre machine (ou Cloud Shell) afin de pouvoir interagir avec Argo CD et de lui fournir des workflows. Il suffit de taper la commande “argo submit” avec pour argument votre manifeste Kubernetes.
argo submit https://raw.githubusercontent.com/litmuschaos/chaos-workflows/master/Argo/argowf-native-pod-delete.yaml -n litmus
ATTENTION 1 :
Argo CD est la brique logicielle de l’architecture Litmus qui va orchestrer les workflows. Celle-ci est asynchrone à Litmus. C’est-à-dire que si vous exécutez un workflow directement depuis Argo CD, celui-ci ne sera pas reporté par Litmus car il n’en est pas le commanditaire. Litmus récupère seulement les résultats des workflows qu’il a exécuté lui-même.
ATTENTION 2 :
Après vos expérimentations, n'oubliez pas de détruire les ressources que vous avez créé avec la commande terraform destroy afin d'éviter des coûts non désirés.
Conclusion
Nous espérons que ce lab vous aura plu. Nous avons essayé de vous faire découvrir et apprécier cet outil prometteur. La résilience et la sécurité sont des enjeux critiques pour une infrastructure. Au travers d’une démarche DevSecOps et GitOps, exploiter un outil de Chaos Engineering tel que Litmus et Argo CD permettent d’attester de la résilience de vos clusters Kubernetes et de facto de les sécuriser.
Ressources
- Site officiel de Litmus : https://litmuschaos.io/
- GitHub officiel de Litmus : https://github.com/litmuschaos/litmus
- Blog officiel de Litmus : https://dev.to/t/litmuschaos
- Documentation officielle de Litmus : https://docs.litmuschaos.io/docs/getstarted/
- Chaos Hub officiel de Litmus : https://hub.litmuschaos.io/
- Tutoriel interactif : https://www.katacoda.com/litmusbot/scenarios/getting-started-with-litmus

Istio sur GKE
Qu’est-ce qu’Istio? On peut se poser la question dans un premier temps, mais qu’est-ce donc qu’Istio ? Istio est un service mesh open source offrant...

GCP: BeyondCorp et Proxy IAP
Introduction Le sujet de la sécurité, et en particulier la gestion des accès et des autorisations, est traité dans certaines compagnies qui migrent...